16장. JBoss EAP 클러스터링
자바기반의 웹 애플리케이션 서버를 사용한 대규모 웹 시스템이 많아지면서 24시간 365일 안정적인 서비스를 제공하면서도 앞으로의 확장성을 보장할 수 있도록 구성하는 것이 매우 중요하게 되었다. 이번 장에서는 웹 애플리케이션 서버를 사용하여 고가용성이 요구되는 웹 시스템을 구축하는 컨설턴트나 관리자, 개발자들에게 JBoss EAP 6 를 활용하기 위해 필요한 내용과 배경 지식에 대해 설명한다.
1.클러스터링 이해
클러스터(Cluster)란 네트워크를 이용하여 마치 하나의 컴퓨터처럼 동작하도록 여러 대의 컴퓨터를 연결하여 구성하는 것을 말한다. 즉 여러 대의 서버들 전체를 한 대의 서버 시스템과 같이 동작하게 하는 기술이나 기능을 말한다. 클라이언트 입장에서는 특정 서버의 상태에 의존하지 않고 클러스터로 묶인 서버 그룹을 마치 하나의 서버에서 서비스를 제공하는 것으로 인식한다. 클러스터 내의 어떤 서버로 접속하든지 동일하게 처리되기 때문에 클라이언트의 요청을 클러스터 멤버에 분산하여 처리하는 것이다. 이렇게 처리함으로써 클라이언트는 여러 개의 서버를 묶은 클러스터가 마치 하나의 서버인 것처럼 보이게 된다.
확장성과 고가용성이 요구되는 웹 시스템에서는 각각의 레이어 마다 고유의 클러스터링 기술을 사용하고 있다. JBoss EAP6를 사용한 웹 시스템 구축에서도 로드밸런싱과 페일오버(failover)를 위해서 클러스터링 기능을 사용한다. JBoss 는 자바 프로세스 단위로 클러스터링을 구성하며, 서버의 물리적인 위치에 관계없이 구성이 가능하다.
특히 고가용성이 요구되는 미션 크리티컬 업무에서 클러스터링은 매우 중요하다. 예를 들어 금융권에서의 인터넷 뱅킹 시스템, 제조업에서 생산공정관리 시스템, 온라인 쇼핑몰 시스템 등의 서비스에서 클러스터를 이용하여 마치 하나의 서버에서 제공하는 것처럼 구성한다. 클러스터링을 통해 특정 서버 장애가 전체 서비스에 영항을 미치지 않도록 구성하는 것이 매우 중요하다.
클러스터를 구성하는 목적은 크게 두 가지로 부하 분산(Load Balancing)과 고가용성(High Availability)이다.
-
부하 분산(Load Balancing)
부하 분산은 클러스터 앞 단에서 모든 클러스터 멤버로 부하를 균등하게 분산하는 것이다. 이론적으로 클러스터를 사용하면 처리량은 클러스터를 구성하는 서버들의 성능을 합친 것이 된다. 처리량을 늘리고 싶다면, 클러스터에 새로운 서버를 추가하여 전체 클러스터의 처리량을 늘릴 수 있다.
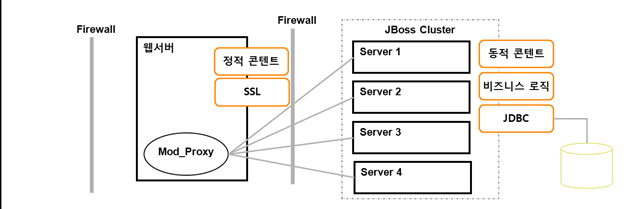
그림 1. 로드 밸런서의 역할
-
고가용성(HA ; High Availability)
고가용성은 클러스터 멤버에 장애가 발생할 경우 다른 멤버가 그 역할을 대신할 수 있도록 하는 것이다. HA 클러스터링은 서비스의 다운 타임을 줄여 준다.
클러스터의 한 서버가 중지될 경우에 다른 서버가 그 역할을 대신(Failover) 처리하여 고가용성을 제공한다. 클러스터링을 구성하여 서비스를 중단 없이 항상 사용 가능한 상태를 유지할 수 있다.

그림 2. 웹 애플리케이션 서버의 HA기능
-
JBoss EAP 6 클러스터
JBoss EAP 6에서는 웹 애플리케이션, EJB 애플리케이션, JMS 기능에 각각 클러스터링을 적용할 수 있다. JBoss EAP 6에는 설정을 편하게 할 수 있도록 프로파일 단위로 클러스터링이 가능한 구성 설정 파일을 제공하고 있다. 파일명의 뒷부분에 ha, full-ha 프로파일이 클러스터링을 제공하는 프로파일이다. 클러스터링을 구현하는 핵심기술은 요청에 대한 로드 밸런싱과 상태를 복제하는 기술이다.
먼저 클러스터링을 구현하기 위한 핵심 기술에 대해서 살펴보고, 웹 애플리케이션, EJB 애플리케이션, JMS에 대한 클러스터링 설정 방법을 설명한다.
2.클러스터링의 핵심기술
JGroups
JGroups는 멀티캐스트 프로토콜을 사용하여 신뢰성 높은 통신을 할 수 있도록 구현된 네트워크 통신 라이브러리이다. JBoss EAP 6의 클러스터링 구현, Infinispan의 네트워크 캐시 구현, HornetQ의 클러스터링 구현 등에 JGroups(http://www.jgroups.org)가 사용된다.
JGroups에서 중요한 프로토콜은 가입과 탈퇴(JOIN/REMOVE), 장애 감지(FD, FD_SOCK) 파티션 결합(MERGE), PING이다.
| 항목 | 설명 |
|---|---|
| 가입(JOIN) | JGroups를 시작할 때 만들어지는 멀티캐스트 그룹 가입을 위한 방식이다. 처음으로 가입하여 다른 멤버가 없으면 리더(코디네이터)가 된다. 멤버가 있으면 기존 리더에게 참가 요청을 하여 멤버 리스트에 추가해 달라고 한다. 그러면 리더가 그룹에 속한 모든 멤버들에게 클러스터 멤버 리스트를 배포하고 정보를 공유한다. |
| 탈퇴(REMOVE) | 탈퇴(REMOVE)은 JGroups 정지시 멀티캐스트 그룹에서 탈퇴하기 위한 것이다. 리더가 아닌 일반 멤버가 탈퇴하는 경우에는 리더가 클러스터 멤버 리스트를 업데이트하고 다른 멤버에게 배포한다. 리더 자신이 탈퇴하는 경우엔 두 번째 멤버가 리더가 되고 클러스터 멤버 리스트를 업데이트하여 다른 멤버에게 배포한다. 마지막 멤버가 탈퇴하면 그 그룹은 없어진다. |
| 장애 감지(FD) | 장애 감지(FD; Failure Detection)는 Heart Beat 메시지를 사용하여 오류가 발생한 멤버를 감지하는 것이다. 각 멤버는 Heart Beat 메시지를 수신하면 응답 메시지를 보내 정상적인 상태 임을 알려야 한다. 지정한 타임아웃 시간 동안 재시도하여 응답을 받지 못하면, 멤버에 오류가 발생한 것으로 간주하여 클러스터 멤버에서 제거한다. |
| 장애 감지 소켓(FD_SOCK) | 장애 감지 소켓(FD_SOCK)은 클러스터 멤버들간에 TCP 소켓으로 A → B → C → A처럼 링 모양으로 연결하여 상태를 모니터링하기 위한 프로토콜이다. 링 모양이기 때문에 각 멤버는 그 이웃 멤버만 감시하게 된다. 멤버 B가 정상 종료할 때는 멤버 A에 메시지를 보내 종료되는 것을 알려준다. 만약, 멤버 B에 장애가 발생하여 갑자기 종료되면, 멤버 A는 연결된 소켓이 비정상 종료되는 것을 감지할 수 있다. 장애를 감지하면 확인 단계를 거치고 장애가 확실하면 클러스터 멤버 리스트에서 삭제한다. |
| 파티션 결합 (MERGE2) | MERGE는 통신 장애 등 여러 가지 이유로 멀티캐스트 그룹이 여러 개로 나뉜 경우 쪼개진 그룹을 하나로 결합하기 위한 것이다. 리더(코디네이터)는 주기적으로 리더가 여기 있다는 멀티캐스트 메시지를 보낸다. 만약 그룹이 쪼개져서 만들어진 다른 그룹의 리더가 이 메시지를 받으면 결합 프로세스를 시작한다. {A, B}와 {C, D, E}을 결합하여 하나의 {A, B, C, D, E}의 그룹으로 만든다. |
| PING | 처음 클러스터의 멤버를 발견하는 데 사용하는 프로토콜이다. 멀티캐스트 주소에 MPING 요청을 보내서 리더(코디네이터)를 찾고 다른 멤버들을 찾는다. 멀티캐스트를 사용할 수 없는 환경에서는 TCPPING이나 GOSSIP 서버를 이용한 TCPGOSSIP, 공유 파일 시스템을 이용한 FILE_PING, 데이터베이스 테이블을 사용하는 JDBC_PING, 아마존 AWS 환경에서 S3(Simple Storage Service)를 사용한 S3_PING, 오픈스택의 Swift를 사용한 SWIFT_PING등 다양한 방식의 PING을 설정할 수 있다. |
표 1. JGroups의 주요 프로토콜
JBoss EAP 6에서는 ha, full-ha 프로파일에 jgroups 서브 시스템이 설정되어 있다. jgroups 서브시스템에는 멀티캐스트를 사용하는 udp 프로토콜 스택과 TCP를 사용하는 tcp 프로토콜 스택이 정의되어 있고, 기본적으로 udp 프로토콜을 사용하도록 설정되어 있다. 아래의 내용을 살펴보면, 방금 설명한 FD, FD_SOCK, PING등 여러 가지 복잡한 값들이 설정되어 있다. 대부분 기본값을 그대로 사용하면 된다.
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="udp">
<stack name="udp">
<transport type="UDP" socket-binding="jgroups-udp"/>
<protocol type="PING"/>
<protocol type="MERGE3"/>
<protocol type="FD_SOCK" socket-binding="jgroups-udp-fd"/>
<protocol type="FD"/>
<protocol type="VERIFY_SUSPECT"/>
<protocol type="pbcast.NAKACK"/>
<protocol type="UNICAST2"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG2"/>
<protocol type="RSVP"/>
</stack>
<stack name="tcp">
<transport type="TCP" socket-binding="jgroups-tcp"/>
<protocol type="MPING" socket-binding="jgroups-mping"/>
<protocol type="MERGE2"/>
<protocol type="FD_SOCK" socket-binding="jgroups-tcp-fd"/>
<protocol type="FD"/>
<protocol type="VERIFY_SUSPECT"/>
<protocol type="pbcast.NAKACK"/>
<protocol type="UNICAST2"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG2"/>
<protocol type="RSVP"/>
</stack>
</subsystem>
다음과 같이 default-stack을 tcp로 변경하면 TCP를 사용하도록 변경할 수 있다.
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="tcp">
멀티캐스트 통신
멀티캐스트 통신은 특정 주소에 참여하는 모든 호스트에 동시에 같은 메시지를 전송하는 통신 방식이다. 멀티캐스트에 사용하는 주소는 IP 주소 상의 D 클래스로 앞의 4 비트가 1110인 224.0.0.0 ~ 239.255.255.255 범위의 주소를 사용한다. 라우터에서 사용하도록 예약된 주소가 있어 실제로 애플리케이션에서 사용할 수 있는 주소는 224.0.1.0 ~ 238.255.255.255 이다.
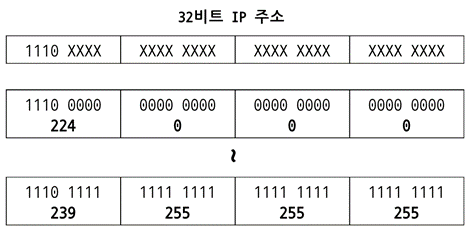
그림 3. 멀티캐스트 주소
멀티캐스트 통신의 장점은 패킷이 멀티캐스트 그룹 단위로 하나만 전송되기 때문에 네트워크 트래픽이 혼잡해지지 않는다는 것이다. 유니캐스트는 멤버 수만큼 여러 번 패킷을 전송해야 한다.
호스트에 여러 개의 네트워크 인터페이스 카드가 있으면 첫 번째 인터페이스를 멀티캐스트 통신에 사용한다. 다음과 같이 설정하면 지정된 인터페이스 카드를 통해 멀티캐스트 통신할 수 있다.
$ route add-net 231.12.21.0 netmask 255.255.255.0 <인터페이스>
IPv6를 사용할 수 있는 운영체제에서는 기본적으로 소켓이 IPv6를 사용하기 때문에 Java가 IPv6를 사용한다. IPv4를 사용하도록 설정하려면 Java 실행 시 다음 옵션을 지정한다.
-Djava.net.preferIPv4Stack=true
멀티캐스트 테스트
멀티캐스트는 먼저 운영체제에서 멀티캐스트할 수 있게 설정되어야 하며, 사용하는 라우터에서도 멀티캐스트 프로토콜을 지원해야 한다. 멀티캐스트가 가능한 환경인지 테스트하는 있는 방법이 필요하다.
jgroups 라이브러리에는 마치 채팅과 같이 멀티캐스트를 사용하여 메시지를 보내는 테스트 애플리케이션을 제공하고 있다.
다음 명령으로 지정한 멀티캐스트 IP, 포트에 참여하여 메시지를 수신하는 애플리케이션을 시작한다.
$ java -cp jgroups-3.2.5.Final.jar org.jgroups.tests.McastReceiverTest -mcast_addr 224.10.10.10 -port 5555
다음 명령으로 지정한 멀티캐스트 IP, 포트로 메시지를 보내는 애플리케이션을 실행하여, 멀티캐스트로 전송할 텍스트 메시지를 입력한다.
$ java -cp jgroups-3.2.5.Final.jar org.jgroups.tests.McastSenderTest -mcast_addr 224.10.10.10 -port 5555
Socket #2=0.0.0.0/0.0.0.0:5555, ttl=32, bind interface=/192.168.0.23
Socket #4=0.0.0.0/0.0.0.0:5555, ttl=32, bind interface=/127.0.0.1
> test
먼저 실행한 멀티캐스트 수신 애플리케이션에 메시지가 수신되면, 멀티캐스트 통신이 정상적으로 동작하는 것이다.
$ java -cp jgroups-3.2.5.Final.jar org.jgroups.tests.McastReceiverTest -mcast_addr 224.10.10.10 -port 5555
Socket=0.0.0.0/0.0.0.0:5555, bind interface=/192.168.0.28
Socket=0.0.0.0/0.0.0.0:5555, bind interface=/127.0.0.1
test [sender=192.168.0.23:5555]
test [sender=192.168.0.23:5555]
3.웹 애플리케이션 클러스터링
웹 애플리케이션의 클러스터링��은 로드 밸런싱과 세션 복제 두 가지 기능이 있다. 일반적인 구성은 다음 그림과 같다.

그림 4. 웹 애플리케이션의 클러스터링 구성
로드 밸런싱
웹 애플리케이션에서 로드 밸런싱은 웹 서버에서 요청을 여러 대의 웹 애플리케이션 서버로 분배하는 기능이다. 이러한 방법으로 여러 서버로 부하를 분산하여, 특정 서버에만 부하가 많아지지 않도록 한다. 또, 설정을 통해 특정 서버 노드에만 부하를 더 주는 것도 가능하다. JBoss EAP 6에서는 웹 서버에서 사용할 수 있는 두 가지 로드 밸런싱 방법이 제공된다.
-
mod_jk 커넥터
mod_jk는 웹 서버에 설치하는 로드 밸런싱 모듈이다. 애플리케이션 서버와 통신에 AJP 프로토콜을 사용한다.
-
mod_cluster 커넥터
mod_cluster는 jboss.org에서 개발되고 있는 Apache 웹 서버와 함께 구성하는 로드 밸런싱 방법이다. 옵션을 웹 서버가 아닌 JBoss에서 설정할 수 있다.
mod_jk 커넥터와 mod_cluster 커넥터에 대한 상세한 내용은 뒷장에서 설명한다.
세션 복제
로드 밸런서는 효율적인 세션의 관리를 위해 스티키(Sticky) 세션을 사용한다. 최초로 접속한 서버에 세션을 저장하�고 계속 해당 서버로만 요청을 한다. 장애가 발생하여 접속한 애플리케이션 서버가 정지해 버리면, 로드밸런스는 다른 서버로 요청을 다시 전송한다. 이때, 요청을 받은 서버에 장애가 발생한 서버에서 생성된 세션 정보가 없으면 더 이상 처리할 수 없다. 일반적으로 세션에는 로그인 정보가 포함되어 있는데, 페일오버 되었을 경우 세션 정보가 없으면 로그아웃된 것으로 인식한다. 이러한 경우를 대비하여 세션 정보를 미리 다른 서버에 전송하고 동기화한다. 이런 기능이 세션 복제이다.
세션 복제 시 주의점
- 클러스터의 SPOF(Single Point Of Failure)를 방지하려면 세션을 하나 이상의 다른 서버에 복제해야 한다.
- HTTP 세션에 저장되는 값은 직렬화(Serializable)된 값이어야 한다.
- 멀티캐스트 주소가 같으면 같은 클러스터로 묶이게 된다. 서로 다른 서비스는 서로 다른 멀티캐스트 주소를 사용해야 한다.
- 성능을 위해서는 내부 클러스터링용으로 별도의 NIC를 사용하는 것이 좋다.
세션 복제 설정 방법
웹 애플리케이션에서 세션 클러스터링을 구성할 때 목적에 따라 적합한 로드 밸런스 모듈과 세션 복제 방법을 결정해야 한다.
| 구분 | 설명 |
|---|---|
| mod_jk를 이��용한 로드 밸런싱 | 로드밸런싱은 기본적으로 웹 서버에서 제공되는 기술이다. mod_jk 로드 밸런싱을 사용하려면, JBoss EAP 6에서는 AJP 커넥터 설정만 하면 된다. ha, full-ha 프로파일에 AJP 커넥터가 설정되어 있다. mod_jk는요청 수나 세션 수를 기반으로 로드 밸런스할 수 있고, Cookie를 이용한 부하분산 설정도 가능하다. 또, 세션유지 관리를 위한 스티키(Sticky) 세션 기능도 제공한다. |
| mod_cluster를 이용한 로드 밸런싱 | mod_cluster 로드밸런싱을 사용하려면, 웹 서버의 설정뿐만 아니라 JBoss EAP 6의 mod_cluster도 설정해야 한다. ha, full-ha 프로파일에 modcluster 서브시스템이 설정되어 있다. mod_cluster는 CPU 부하나 메모리 상황 등에 따라 동적으로 로드 밸런싱 할 수 있다. JBoss 인스턴스 자동 등록, 동적으로 부하를 계산하여 로드 밸런싱하는 등 클라우드 환경를 지원하기 위한 많은 기능을 제공한다. mod_cluster와 애플리케이션 서버간 통신에는 AJP 프로토콜뿐만 아니라 HTTP, HTTPS 프로토콜도 사용할 수 있고, 스티키(Sticky) 세션도 지원한다. |
표 2. 로드 밸런싱 모듈 비교
ha, full-ha 프로파일에는 세션이 복제되도록 설정되어 있기 때문에, 이 프로파일을 사용하는 JBoss EAP 6 인스턴스를 여러 개 기동하면, 자동으로 클러스터를 구성하여 세션을 복제한다.
22:55:56,248 INFO [org.jboss.as.clustering.infinispan] (ServerService Thread Pool -- 56) JBAS010281: Started default-host/session cache from web container
22:55:56,255 INFO [org.jboss.as.clustering.infinispan] (ServerService Thread Pool -- 55) JBAS010281: Started repl cache from web container
22:55:56,264 INFO [org.jboss.as.clustering] (MSC service thread 1-2) JBAS010238: Number of cluster members: 2
실제 세션이 복제되려면, 웹 애플리케이션에 세션을 복제하겠다는 설정이 필요하다. 웹 애플리케이션의 설정이 없으면 ha 프로파일을 사용하여 클러스터링이 구성되어 있어도, 세션은 복제되지 않는다. 웹 애플리케이션에 세션을 복제하겠다는 설정은 web.xml 파일에 <distributable/> 태그를 추가하면 된다.
다음은 web.xml에 <distributable/>을 추가한 예이다.
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" id="WebApp_ID" version="3.0">
<display-name>session</display-name>
<distributable/>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
이외에는 일반 웹 애플리케이션을 작성하는 방법과 같다.
세션 복제 상세설정
WEB-INF/jboss-web.xml 파일에서 세션 복제에 대한 상세한 설정을 지정할 수 있다. 다음은 세션 설정의 예이다.
<jboss-web>
<context-root>/</context-root>
<replication-config>
<cache-name>custom-session-cache</cache-name>
<replication-trigger>SET</replication-trigger>
<replication-granularity>ATTRIBUTE</replication-granularity>
<use-jk>false</use-jk>
<max-unreplicated-interval>30</max-unreplicated-interval>
<snapshot-mode>INSTANT</snapshot-mode>
<snapshot-interval>1000</snapshot-interval>
<session-notification-policy>com.example.CustomSessionNotificationPolicy</session-notification-policy>
</replication-config>
</jboss-web>
��세션이 언제 복제될 것인지를 <replication-trigger>를 사용하여 설정할 수 있다. 사용할 수 있는 옵션은 다음과 같다.
- SET : 세션이 설정될 때 복제
- SET_AND_GET : 세션을 읽기만 해도 복제
- SET_AND_NON_PRIMITIVE_GET : 세션이 설정될 때와 Java의 Primitive 타입이 아닌 타입은 읽을 때도 복제. 기본 설정값.
또, <replication-granularity>를 사용하여 세션 복제 범위를 지정할 수 있다. 기본값은 SESSION으로 세션에 보관된 객체 전체를 복제한다. 애트리뷰트 (attribute)를 사용하면 세션 객체 중 변경된 애트리뷰트 (attribute)만 복제하기 때문에 세션 복제 속도를 크게 향상할 수 있다.
세션 타임아웃 설정
HTTP 프로토콜은 연결되지 않은 상태로 통신하기 때문에 브라우저의 쿠키와 서버의 세션을 사용하여 서로의 상태를 유지한다. 연결되지 않은 상태이기 때문에 사용자가 웹 애플리케이션을 계속 사용하고 있는지 판단할 수 없다. 그래서 지정된 시간 동안 세션을 사용하지 않으면, 그 세션을 삭제하는 세션 타임아웃 기능을 사용한다. 웹 애플리케이션의 세션 타임아웃은 web.xml 파일의 <session-config>에서 설정한다. jboss-web.xml 파일에서도 세션 타임아웃값을 다음과 같이 설정할 수 있다.
<jboss-web>
<session-config>
<session-timeout>120</session-timeout>
</session-config>
</jboss-web>
세션 Passivation
세션에 너무 많은 데이터가 들어 있으면 어떻게 될까? 세션은 기본적으로 메모리, 즉 Java의 Heap메모리를 사용하기 때문에 OutOfMemory 오류가 발생할 수 있다. 그래서 기본적으로 세션에는 최소한의 값만 저장하는 것이다.
하지만 이미 개발된 애플리케이션을 수정하기 어렵다면 이런 방법을 사용할 수 있다.
패시베이션(Passivation)은 자주 사용되지 않는 세션을 메모리에서 삭제하고 디스크에 저장하여 메모리를 효율적으로 사용하는 방법이다. 반대로 액티베이션(Activation)은 디스크에 저장된 데이터를 메모리에 읽어 들이는 것을 말한다.
HTTP 세션의 패시베이션은 다음 3가지 상황에서 발생한다.
- 새로운 세션을 만들려고 할 때, 이미 최대 액티브 세션 수를 넘었기 때문에 서버는 세션 일부를 디스크에 저장하고 새 세션을 만든다.
- 주기적으로 백그라운드 작업을 통해 세션을 디스크에 저장한다.
- 웹 애플리케이션이 배포되어 있고 새로 배포되는 웹 애플리케이션의 세션 관리자가 다른 서버의 세션 백업 본을 가져오는 경우에 세션이 패시베이션 될 수 있다.
세션 패시베이션 설정
세션 패시베이션은 애플리케이션 WEB_INF/jboss-web.xml 파일에 설정한다.
<jboss-web>
<max-active-sessions>20</max-active-sessions>
<passivation-config>
<use-session-passivation>true</use-session-passivation>
<passivation-min-idle-time>60</passivation-min-idle-time>
<passivation-max-idle-time>600</passivation-max-idle-time>
</passivation-config>
</jboss-web>
세션 패시베이션 설정 항목들은 다음과 같다.
| 구분 | 설명 | 기본값 |
|---|---|---|
<max-active-sessions> | 허용되는 세션의 최대 수. 패시베이션을 사용할 때 세션 수가 이 값을 초과하면 설정된 <passivation-min-idle-time>을 초과한 세션들이 저장된다. 그래도 허용 세션 수를 제한을 초과하면 새로운 세션을 만들지 못한다. | -1 (제한없음) |
<use-session-passivation> | 세션 패시베이션을 사용할 것인지 설정 | false |
<passivation-min-idle-time> | 최대 세션 수를 유지하기 위해 패시베이션될 때 이 시간만큼 사용되지 않은 세션이 대상이 된다. | -1 |
<passivation-max-idle-time> | 지정된 시간 이상 사용되지 않은 세션이 패시베이션 된다. 최대 세션 수와 상관없이 지정된 시간이 되면 패시베이션 된다. web.xml의 <session-timeout> 설정보다 작은 값으로 설정해야 한다. | -1 |
표 3. 패시베이션 설정 항목
쿠키 도메인
쿠키 도메인은 애플리케이션을 사용하는 클라이언트의 웹 브라우저에서 쿠키를 읽을 수 있는 호스트를 지정하는 방법이다. 쿠키 도메인의 기본값은 ‘/’ 이다. 기본적으로 쿠키를 만든 호스트에서만 쿠키의 내용을 읽을 수 있다. 다른 호스트에서도 쿠키의 내용을 읽을 수 있게 하려고 쿠키 도메인을 설정한다.
예를 들어 SSO(Single Sign On)을 사용하여 로그인 정보를 공유하기 위해 SSO 밸브를 사용하여 쿠키 도메인을 설정하는 방법을 살펴보자. 다음 설정은 다른 서버에서 실행되는 서로 다른 애플리케이션이 http://app1.opennaru.com 와 http://app2.opennaru.com 에서 SSO 컨텍스트를 공유할 수 있는 설정이다.
쿠키 도메인 설정 예
<Valve className="org.jboss.web.tomcat.service.sso.ClusteredSingleSignOn"
cookieDomain="opennaru.com"/>
TCP 클러스터링 방법
jgroups 서브시스템의 default-stack을 tcp로 변경하면 멀티캐스트가 아닌 TCP를 사용한다고 설명했다. 하지만 멀티캐스트가 전혀 동작하지 않는 아마존 웹 서비스(AWS)와 같은 환경에서는 이 설정만으로는 동작하지 않는다.
그 이유는 tcp 스택으로 변경하더라도 tcp 스택에 클러스터 멤버를 찾기 위한 PING 프로토콜로 멀티캐스트를 사용하는 MPING을 사용하도록 설정되어 있기 때문이다.
<protocol type="MPING" socket-binding="jgroups-mping"/>
멀티캐스트를 사용하지 않는 PING 프로토콜로 변경해야 한다. 멀티캐스트를 사용하지 않는 경우에는 TCPPING, FILE_PING, S3_PING, TCPGOSSIP, JDBC_PING등 다양한 PING 프로토콜들이 있다. 이 방법 중 다음에서 TCPPING 설정방법을 살펴보자.
다음과 같이 TCPPING의 initial_hosts 프로퍼티로 호스트의 IP와 포트를 지정하면 된다. 시스템 프로퍼티로 값을 변경할 수 있도록 값을 설정하였다.
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="tcp">
… 생략 …
<stack name="tcp">
<transport type="TCP" socket-binding="jgroups-tcp"/>
<protocol type="TCPPING">
<property name="initial_hosts">${jgroups.tcpping.initial_hosts:192.168.0.11[7600],192.168.0.11[7700], 192.168.0.12[7600],192.168.0.12[7700]}</property>
<property name="port_range">0</property>
<property name="timeout">3000</property>
<property name="num_initial_members">3</property>
</protocol>
<protocol type="MERGE2"/>
<protocol type="FD_SOCK" socket-binding="jgroups-tcp-fd"/>
<protocol type="FD"/>
<protocol type="VERIFY_SUSPECT"/>
<protocol type="pbcast.NAKACK"/>
<protocol type="UNICAST2"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG2"/>
<protocol type="RSVP"/>
</stack>
4.웹 서버 설치
JBoss EAP 6에 포함된 웹 서버인 Apache HTTPD는 레드햇 고객 서비스 포탈에서 다운로드 할 수 있다.
웹 서버 설치 방법은 다음과 같다. 웹 서버는 80포트를 사용하기 때문에 root 계정으로 실행해야 한다.
따라하기
- JBoss EAP 6 Apache HTTP Server 다운로드
- 필요 패키지 설치
- 다운로드한 Apache HTTP Server 파일 압축 풀기
- postinstall 실행
- 웹 서버 실행
- 웹 서버 실행 확인
- 웹 서버 정지
-
JBoss EAP 6 Apache HTTP Server 다운로드
Red Hat 고객 서비스 포탈(http://access.redhat.com)에서 JBoss EAP 6 다운로드 목록으로 이동한다.
목록에서 운영체제와 아키텍처에 해당하는 Apache HTTP Server 바이너리를 찾아 다운로드 한다.
-
필요 패키지 설치
웹 서버에 필요한 패키지를 설치한다.
$ sudo yum install nss elinks apr-devel apr-util-devel krb5-workstation mod_auth_kerb
-
다운로드한 Apache HTTP Server 파일 압축 풀기
웹 서버를 설치할 디렉터리에 ZIP파일의 압축을 푼다.
$ cd EAP6book/web
$ unzip ~/Downloads/jboss-ews-httpd-2.0.1-RHEL6-x86_64.zip -
postinstall 실행
설치된 웹 서버의 httpd디렉터리에서 .postinstall 을 실행한다.
$ cd jboss-ews-2.0/httpd
$ ./.postinstall
-
웹 서버 실행
웹 서버를 실행한다.
$ cd sbin
$ sudo ./apachectl start -
웹 서버 실행 확인
해당 서버 IP 로 접속하여 서비스가 정상인지를 확인한다.
-
웹 서버 정지
웹 서버 정지방법은 아래와 같다.
$ ./apachectl stop
만약 웹 브라우저에서 웹 서버로 접속되지 않을 경우에는 아래와 같이 방화벽을 중지 한 후 다시 접속을 시도 한다.
$ sudo service iptables stop
iptables: Flushing firewall rules: [ OK ]
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Unloading modules: [ OK ]
이후에도 방화벽 사용을 계속 중지하려면 다음과 같이 설정한다.
$ sudo chkconfig iptables off
5.웹 커넥터 종류
웹 서버는 요청을 애플리케이션 서버나 또는 웹 애플리케이션 서버 클러스터에 전달한다. Apache HTTPD Server를 기반 제품인 JBoss EWS(Enterprise Web Server)에서 사용할 수 있는 커넥터는 mod_jk, mod_proxy, mod_cluster 모듈들이 있다. 또, Microsoft IIS 서버에서 사용할 수 있는 커넥터와 Sun ONE Web Server에서 사용할 수 있는 커넥터가 있다.
가장 최근에 만들어진 mod_cluster는 클러스터의 노드들을 자동으로 찾아 로드 밸런싱하는 기능을 제공한다. 또 애플리케이션 배포를 감지하여 애플리케이션이 배포된 노드에만 요청을 전달할 수 있는 기능도 제공하고 있다.
| 커넥터 | 웹서버 | 운영체제 | 프로토콜 | 애플리케이션 상태 지원 | 스티키세션 |
|---|---|---|---|---|---|
| mod_cluster | JBoss EWS(Apache HTTPD) | RHEL 5/6 Windows 2008 Server Solaris 10/11 | AJP, HTTP, HTTPS | O | O |
| mod_jk | JBoss EWS(Apache HTTPD) | RHEL 5/6 Windows 2008 Server Solaris 10/11 | AJP | X | O |
| mod_proxy | JBoss EWS(Apache HTTPD) | RHEL 5/6 Windows 2008 Server Solaris 10/11 | HTTP, HTTPS | X | O |
| ISAPI | Microsoft IIS | Windows 2008 Server | AJP | X | O |
| NSAPI | Sun ONE Web Server | Solaris 10/11 | AJP | X | O |
표 4. 웹 서버 커넥터의 종류와 주요 특징
6.mod_jk 커넥터
mod_jk 개요
아파치 웹 서버는 전세계적으로 가장 많이 사용되는 대표적인 웹 서버이며 플러그인 모듈을 사용하여 확장 할 수 있다.
mod_jk 커넥터는 아파치 웹 서버에 로드되는 mod_jk.so 모듈이다. 이 모듈은 클라이언트 요청을 받아 JBoss EAP에 전송하고, JBoss EAP는 이 요청을 받아 웹 서버에 보낸다.
mod_jk 설정 방법
점검 사항
- 앞에서 언급한 “JBoss EAP 6 Apache HTTP 서버 설치”에 따라 웹 서버가 설치되어 있어야 한다.
- root 권한을 사용하여 설치해야 한다.
mod_jk 설정 절차
따라하기
- mod_jk.conf 파일 작성
- workers.properties 파일 작성
- 웹 커넥터 라이브러리를 다운로드
- HTTPD 모듈 디렉터리에 mod_jk.so 파일 복사
- 웹 서버 restart
- jkstatus를 통해 정상 동작 확인
-
mod_jk.conf 파일 작성
Apache HTTP서버가 설치된 디렉터리의
conf.d디렉터리($HTTPD_HOME/conf.d) 에서mod_jk.conf파일을 열어 아래의 내용들을 참조하여 환경에 맞게 작성한다.# Load mod_jk module
# Update this path to match your modules location
LoadModule jk_module modules/mod_jk.so
# Where to find workers.properties
# Update this path to match your conf directory location (put workers.properties next to httpd.conf)
JkWorkersFile conf.d/workers.properties
# Where to put jk logs
# Update this path to match your logs directory location (put mod_jk.log next to access_log)
JkLogFile logs/mod_jk.log
JkShmFile logs/mod_jk.shm
# Set the jk log level [debug/error/info]
JkLogLevel info
# Select the log format
JkLogStampFormat "[%a %b %d %H:%M:%S %Y] "
# JkOptions indicate to send SSL KEY SIZE,
JkOptions +ForwardKeySize +ForwardURICompat -ForwardDirectories +ForwardURICompatUnparsed
# JkRequestLogFormat set the request format
JkRequestLogFormat "%w %V %T"
# Send everything for context /examples to worker named worker1 (ajp13)
JkMount /*.jsp lb
JkMount /*.do lb
JkMount /*.mvc lb
JkMount /jkstatus* jkstatus
# Add jkstatus for managing runtime data
<Location /jkstatus>
JkMount jkstatus
Order Deny,Allow
Allow from 127.0.0.1
Allow from 192
Deny from all
</Location> -
workers.properties 파일 작성
Apache HTTP서버가 설치된 디렉터리의 conf.d 디렉터리(
$HTTPD_HOME/conf.d/) 에서workers.properties파일을 열어 아래의 내용들을 참조하여 환경에 맞게 작성한다.여기서 주의할 것은
worker.properties에balance_worker리스트에 호스트명과 JBoss EAP의instance-id와 같아야 한다. 여기서instance-id는server1,server2로 지정한다.worker.list=lb,jkstatus
# Templates
worker.template.type=ajp13
worker.template.maintain=60
worker.template.lbfactor=1
worker.template.ping_mode=A
worker.template.ping_timeout=2000
worker.template.prepost_timeout=2000
worker.template.socket_timeout=60
worker.template.socket_connect_timeout=2000
worker.template.socket_keepalive=true
worker.template.connection_pool_timeout=60
worker.template.connect_timeout=10000
worker.template.recovery_options=7
# Set properties for server1 (ajp13)
worker.server1.reference=worker.template
worker.server1.host=127.0.0.1
worker.server1.port=8009
# Set properties for server2 (ajp13)
worker.server2.reference=worker.template
worker.server2.host=127.0.0.1
worker.server2.port=8109
worker.lb.type=lb
worker.lb.balance_workers=server1,server2
worker.lb.method=Session
worker.lb.sticky_session=True
worker.jkstatus.type=status -
웹 커넥터 라이브러리를 다운로드
레드햇 고객 포탈에 접속하여 OS 플랫폼에 맞는 JBoss EAP 6 의 웹 커넥터 네이티브 패키지를 다운로드한다.

-
HTTPD 모듈 디렉터리에 mod_jk.so 파일 복사
-
다운로드한 웹 커넥터 네이티브 패키지 압축을 푼다.
$ cd /EAP6book/jboss
$ unzip ~/Downloads/jboss-eap-native-webserver-connectors-6.2.0-RHEL6-x86_64.zip
Archive: /home/admin/Downloads/jboss-eap-native-webserver-connectors-6.2.0-RHEL6-x86_64.zip
creating: jboss-eap-6.2/modules/system/layers/base/native/
creating: jboss-eap-6.2/modules/system/layers/base/native/etc/
… 생략 …
creating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_jk.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_manager.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_advertise.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_proxy_cluster.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_slotmem.so
inflating: jboss-eap-6.2/SHA256SUM -
mod_jk.so 파일을
$HTTPD_HOME/modules에 복사한다.$ cd /EAP6book/jboss/jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/
$ cp mod_jk.so /EAP6book/web/jboss-ews-2.0/httpd/modules/
-
-
웹 서버 restart
-
mod_jk 환경 설정 후 웹 서버를 restart 한다.
$ cd /EAP6book/web/jboss-ews-2.0/httpd/sbin
$ sudo ./apachectl restart
-
-
jkstatus를 통해 정상 동작 확인
-
http://localhost/jkstatus 에 접속하여 정상 작동 확인

-
mod_jk.conf 설정 항목
| 구분 | 설정방법 | 예제 |
|---|---|---|
| JkMount | JkMount 는 웹서버가 mod_jk 모듈로 전송할 URL을 지정한다. 지시어 설정에 따라 mod_jk는받은 URL을 올바른 Servlet 컨테이너에 전송한다. | 정적 콘텐트는 웹서버에서 제공하고 Java 애플리케이션만 부하 분산을 사용하려면 URL 경로가 /application/* 이거나 확장자를 사용하여 /.jsp와 같이 지정한다. JkMount /.jsp lb |
| JKMountFile | mod-jk.conf 의 JKMount 외에도, mod_jk에 전달되는 여러 URL 패턴을 포함하는 별도의 파일을 지정할 수 있다. | 여러 URL 패턴을 설정하기 위해서 $HTTPD_HOME/conf/ uriworkermap.properties라는 파일을 만든다. JkMountFile conf/uriworkermap.properties |
표 5. mod_jk 설정항목
workers.properties 설정
workers.properties 파일은 클라이언트 요청을 전달하는 워커 노드의 동작을 정의한다. 이 파일은 $HTTPD_HOME/conf/workers.properties에 있다. workers.properties 파일은 웹 서버와 연결되는 여러 개의 서블릿 컨테이너의 위치와 컨테이너 전체에 부하를 분산시키는 방법을 정의한다.
설정은 크게 세가지 부분으로 구성된다.
- 모든 워커 노드에 적용되는 전역 프로퍼티
- 각각의 워커에게 적용되는 설정
- 로드 밸런싱을 위한 워커 리스트 설정
프로퍼티의 구조는 worker.WORKER_NAME이다. WORKER_NAME가 워커의 고유 이름이고, JBoss EAP 6의 웹 서브시스템에서 설정한 instance-id와 같은 이름이어야 한다.
| 구분 | 항목 | 설명 |
|---|---|---|
| 전역 프로퍼티 | worker.list | mod_jk에서 사용하는 워커 리스트. 이 워커들이 요청을 받을 수 있다. |
| 워커 리스트 | type | 워커의 타입. 기본 타입은 ajp13 이다. 가능한 타입은 ajp14, lb, status이다. lb는 로드 밸런싱 타입이고, status는 mod_jk의 상태를 출력하기 위해 사용된다. |
| balance_workers | 로드 밸런서가 관리할 워커를 지정한다. 컴마로 구분한 워커 리스트를 작성한다. | sticky_session |
| 같은 세션에 대한 요청이 항상 같은 워커로 라우팅할 것인를 지정한다. 기본값은 0으로 스티키 세션을 사용하지 않는다. 스티키 세션을 사용하려면 1이나 True로 설정한다. 로그인이 필요한 애플리케이션이면 일반적으로 스티키 세션을 사용하도록 설정해야 한다. .5+ | 워커 | host |
| 워커의 호스트 이름 또는 IP 주소. 기본값은 localhost 이다. | port | JBoss 서버 인스턴스의 AJP포트 번호. 기본값은 8009이다. |
| ping_mode | JBoss 서버의 상태를 검사하는 방법을 지정한다. 검사방법은 CPing이라는 빈 AJP13 패킷을 보내 응답 CPong을 받는다. ping_mode는 C, P, I, A를 조합하여 사용한다. * C - Connect. 서버에 연결한 후 한 번만 연결을 검사한다. connect_timeout 값을 사용하여 제한 시간을 지정한다. 지정하지 않으면 ping_timeout 을 사용한다. * P - Prepost. 서버에 요청을 보내기 전에 연결을 검사한다. prepost_timeout 을 사용하여 제한 시간을 지정한다. 지정하지 않으면 ping_timeout 을 사용한다. * I - Interval. connection_ping_interval에 지정된 간격으로 연결을 검사한다. * A - All. 위의 모든 연결 검사 방법을 사용하도록 설정한다. | ping_timeout, connect_timeout, prepost_timeout, connection_ping_interval |
| 연결 검사 설정의 제한 값. 값은 밀리 초 단위이다. ping_timeout 의 기본값은 10000이다. | lbfactor | 각 워커의 부하 분산 지수를 지정한다. 이것은 더 사양이 좋은 서버에 더 많은 부하를 할당하는 경우에 사용한다. 예를 들어 특정 워커에 다른 워커의 3배 부하를 할당하려면 3으로 설정한다. worker.my_worker.lbfactor=3 |
표 . worker 설정 항목
JBoss EAP 6에 AJP설정
JBoss EAP 6 와 JBoss EAP 6 Apache HTTP Server를 mod_jk 로 연결하기 위해서는 웹 서버와 mod_jk 커넥터가 설치되어 있어야 한다. 설치되어 있지 않으면 먼저 설치한다.
-
- 웹 서버 설치에 따라 웹 서버가 설치되어 있어야 한다.
-
- mod_jk 커넥터 설정방법에 따라 커넥터가 설정되어 있어야 한다.
작업 수행
아래와 같이 웹 서버와 JBoss EAP 6 인스턴스 2개를 Port Off Set을 100으로하여 같은 머신에서 구성한다. 웹 서버의 구성 부분은 앞서 설명한 JBoss EAP 6 Apache HTTP Server 구성과 mod_jk 구성과 같은 내용이므로 필요한 경우 앞의 내용을 참조하여 진행한다. 다음에서는 웹 서버의 주요 구성 환경에 대해서만 간단히 절차에 포함하였다.
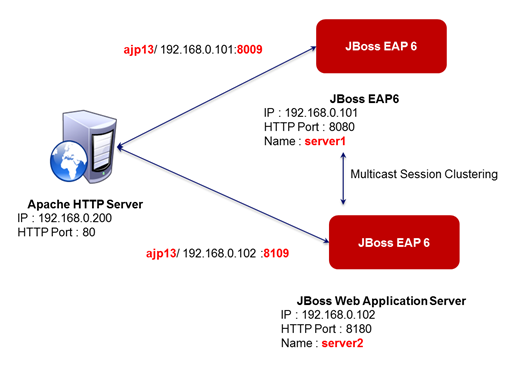
그림 6. 웹 서버와 JBoss 인스턴스의 연결 구성
그림에서는 3개의 서버에 웹 서버와 JBoss EAP 6를 설치하는 구성으로 설명하였지만, 따라하기에서는 웹 서버와 JBoss EAP 6 인스턴스를 모두 한 머신에서 설정하는 것으로 설명하고 있다.
따라하기
- mod_jk.conf 파일 작성
- workers.properties 파일 작성
- HTTPD 모듈 디렉터리에 mod_jk.so 파일 복사
- standalone-ha.xml 파일 수정
- JBoss server1 실행 스크립트 작성
- server1 에 session.war 파일 배포
- JBoss server2 실행 스크립트 작성
- server2 에 session.war 파일 배포
-
mod_jk.conf 파일 작성
Apache HTTPD서버가 설치된 디렉터리의
conf.d하위 디렉터리($HTTPD_HOME/conf.d)에mod_jk.conf파일을 아래의 내용들을 참조하여 환경에 맞게 작성한다.# Load mod_jk module
# Update this path to match your modules location
LoadModule jk_module modules/mod_jk.so
# Where to find workers.properties
# Update this path to match your conf directory location (put workers.properties next to httpd.conf)
JkWorkersFile conf.d/workers.properties
# Where to put jk logs
# Update this path to match your logs directory location (put mod_jk.log next to access_log)
JkLogFile logs/mod_jk.log
JkShmFile logs/mod_jk.shm
# Set the jk log level [debug/error/info]
JkLogLevel info
# Select the log format
JkLogStampFormat "[%a %b %d %H:%M:%S %Y] "
# JkOptions indicate to send SSL KEY SIZE,
JkOptions +ForwardKeySize +ForwardURICompat -ForwardDirectories +ForwardURICompatUnparsed
# JkRequestLogFormat set the request format
JkRequestLogFormat "%w %V %T"
# Send everything for context /examples to worker named worker1 (ajp13)
JkMount /*.jsp lb
JkMount /*.do lb
JkMount /*.mvc lb
JkMount /jkstatus* jkstatus
# Add jkstatus for managing runtime data
<Location /jkstatus>
JkMount jkstatus
Order Deny,Allow
Allow from 127.0.0.1
Allow from 192.168
Deny from all
</Location> -
workers.properties 파일 작성
Apache HTTP서버가 설치된 디렉터리의
conf.d하위 디렉터리($HTTPD_HOME/conf.d/) 에workers.properties파일을 아래의 내용을 참조하여 환경에 맞게 작성한다.여기서 주의할 것은
worker.properties에balance_worker리스트에 호스트명과 JBoss EAP의instance-id명이 같아야 한다. 여기서instance-id명은server1,server2로 지정한다.worker.list=lb,jkstatus
# Templates
worker.template.type=ajp13
worker.template.maintain=60
worker.template.lbfactor=1
worker.template.ping_mode=A
worker.template.ping_timeout=2000
worker.template.prepost_timeout=2000
worker.template.socket_timeout=60
worker.template.socket_connect_timeout=2000
worker.template.socket_keepalive=true
worker.template.connection_pool_timeout=60
worker.template.connect_timeout=10000
worker.template.recovery_options=7
# Set properties for server1 (ajp13)
worker.server1.reference=worker.template
worker.server1.host=127.0.0.1
worker.server1.port=8009
# Set properties for server2 (ajp13)
worker.server2.reference=worker.template
worker.server2.host=127.0.0.1
worker.server2.port=8109
worker.lb.type=lb
worker.lb.balance_workers=**server1,server2**
worker.lb.method=Session
worker.lb.sticky_session=True
worker.jkstatus.type=status -
HTTPD 모듈 디렉터리에 mod_jk.so 파일 복사
-
mod_jk.so 파일을
$HTTPD_HOME/modules/디렉터리에 복사한다.$ cd /EAP6book/jboss/jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/
$ cp mod_jk.so /EAP6book/web/jboss-ews-2.0/httpd/modules/복사한 후 Apache HTTP Server 를 재기동한다.
$ cd /EAP6book/web/jboss-ews-2.0/httpd/sbin
$ sudo ./apachectl restart
-
-
standalone-ha.xml 파일 수정
- standalone-ha.xml 파일의 웹 서브시스템에
instance-id속성을 추가한다.
- standalone-ha.xml 파일의 웹 서브시스템에
$ vi $JBOSS_HOME/standalone/configuration/standalone-ha.xml
- 웹 서브시스템을 찾아 환경변수
jboss.node.name을 사용할 수 있도록instance-id속성을 ��추가한다.
<subsystem xmlns="urn:jboss:domain:web:1.5" default-virtual-server="default-host" instance-id="${jboss.node.name}" native="false">
-
JBoss server1 실행 스크립트 작성
-
$JBOSS_HOME/server1디렉터리에서server1.sh실행 스크립트를 작성한다.$ cd $JBOSS_HOME
$ cp -R standalone server1
$ cd server1
$ vi server1.sh -
server1.sh 파일의 내용을 다음과 같이 작성한다.
#!/bin/sh
$JBOSS_HOME/bin/standalone.sh -c standalone-ha.xml -b 127.0.0.1 -bmanagement 127.0.0.1 -Djboss.socket.binding.port-offset=0 -Djboss.node.name=server1 -Djboss.server.base.dir=$JBOSS_HOME/server1 -
server1.sh파일에 실행 권한을 부여한다.
$ chmod u+x server1.shserver1.sh을 실행하여 JBoss EAP 6server1인스턴스를 실행한다.
$ ./server1.sh -
-
server1에session.war파일 배포-
http://localhost:9990/console/에 접속하여
server1인스턴스에session.war파일을 배포한다. -
session.war파일은 세션에 Integer값을 하나 저장하고 요청 때마다 세션에 저장된 값을 하나씩 증가시키는 간단한 JSP 프로그램이다. http://github.com/nameislocus/session에서 다운로드할 수 있다. Runtime Manage Deployments Add를 클릭하여 session.war 파일을 선택하고 ‘Save’한다. ‘En/Disable’ 버튼을 클릭하여session.war애플리케이션을 Enable한다.
-
-
JBoss
server2실행 스크립트 작성-
$JBOSS_HOME/bin디렉터리에서server2.sh실행 스크립트를 작성한다.$ cd $JBOSS_HOME
$ cp -R standalone server2
$ cd server2
$ vi server2.sh -
server2.sh파일의 내용을 다음과 같이 작성한다.#!/bin/sh
$JBOSS_HOME/bin/standalone.sh -c standalone-ha.xml -b 127.0.0.1 -bmanagement 127.0.0.1 -Djboss.socket.binding.port-offset=100 -Djboss.node.name=server2 -Djboss.server.base.dir=$JBOSS_HOME/server2 -
server2.sh파일에 실행 권한을 부여한다.
$ chmod u+x server2.sh- server2.sh을 실행하여 JBoss EAP 6 server2 인스턴스를 실행한다.
$ ./server2.sh -
-
server2에session.war파일 배포-
http://localhost:10090/console/ 에 접속하여
server2인스턴스에도session.war파일을 배포한다. ⑥과 같은 방법으로 ***server2***에도 배포한다.JBoss EAP 6
server1과server2에 대한 웹 콘솔 접속 아이디와 패스워드는 3장에서 설치시 설정했던admin과opennaru!234이다.
-
mod_jk 구성 테스트
mod_jk 로 연결된 웹 서버와 JBoss EAP 6 인스턴스 간의 로드 밸런싱과 세션복제 상태를 검증한다. 먼저 mod_jk의 구성이 잘 되어 정상적으로 기동되었는지 확인하여야 한다.
웹 브라우저에서 http://localhost/jkstatus/ 로 접속하면 다음 그림과 같이 mod_jk와 JBoss 인스턴스 간의 연결 상태가 표시된다.
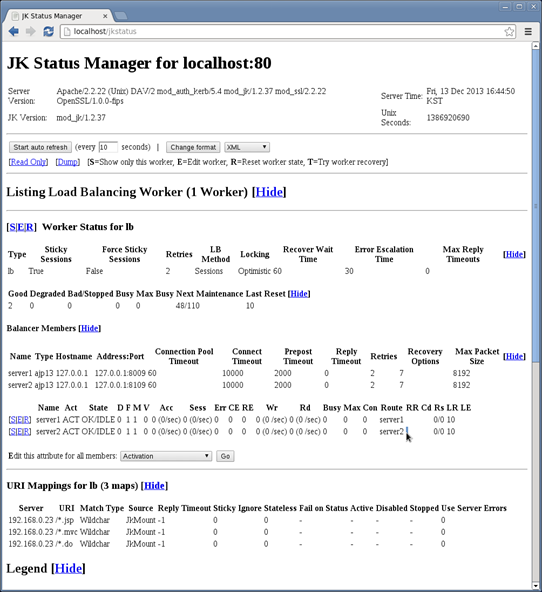
그림 7. mod_jk 상태 모니터링 페이지
이제 세션 복제가 되고 있는지 웹 브라우저를 사용하여 테스트해보자.
웹 브라우저에서 요청을 보내면 웹 서버는 mod_jk를 통해 연결된 JBoss 인스턴스로 요청을 전달한다. 접속된 JBoss 인스턴스를 정지시켰을 때 정상적으로 다른 JBoss 인스턴스에 요청이 전달되고 세션 정보가 업데이트되는지를 확인한다.
따라하기
- 1번째 요청 전송
- 접속한 1번 JBoss 인스턴스 정지
- 2번째 요청 전송
- 정지 상태인 1번 JBoss 인스턴스를 다시 실행
- 2번 JBoss 인스턴스 정지
- 3번째 요청 전송
-
1번째 요청 전송
-
웹 브라우저를 열고 http://localhost/session/index.jsp URL을 입력하여 웹 서버로 1번째 요청을 보내면 다음과 같이 ��세션 ID를 표시하는 페이지가 출력된다. 세션 ID의 뒤에
.server1이 접속한 JBoss 인스턴스의instance-id이다. -
여기서 ‘1 times’로 표시된 것은 세션에 저장된 숫자 값이다.

-
-
접속한 1번 JBoss 인스턴스 정지
-
Ctrl + C를 눌러 세션이 생성된 JBoss 인스턴스server1을 중지한다.17:20:27,265 INFO [org.jboss.as] (Controller Boot Thread) JBAS015951: Admin console listening on http://127.0.0.1:9990
17:20:27,266 INFO [org.jboss.as] (Controller Boot Thread) JBAS015874: JBoss EAP 6.2.0.GA (AS 7.3.0.Final-redhat-14) started in 19045ms - Started 175 of 299 services (123 services are passive or on-demand)
17:20:28,919 INFO [org.jboss.as.clustering] (Incoming-1,shared=udp) JBAS010225: New cluster view for partition web (id: 1, delta: 1, merge: false) : [server1/web, server2/web]
17:20:28,920 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-1,shared=udp) ISPN000094: Received new cluster view: [server1/web|1] [server1/web, server2/web]
17:21:00,889 INFO [stdout] (ajp-/127.0.0.1:8009-1) session=ABrqVi3VCi74JLu1Smwe+p8U.server1
^C
… 생략 …
17:21:16,211 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-2) ISPN000082: Stopping the RpcDispatcher
17:21:16,228 INFO [org.jboss.as] (MSC service thread 1-1) JBAS015950: JBoss EAP 6.2.0.GA (AS 7.3.0.Final-redhat-14) stopped in 564ms
-
-
2번째 요청 전송
-
웹 브라우저에서 ‘새로 고침’을 클릭하여 웹 서버로 2번째 요청을 보내면 세션 ID가
.server2로 변경된다. -
세션에 저장된 숫자 값이 ‘2’로 변경된 것을 확인할 수 있다.
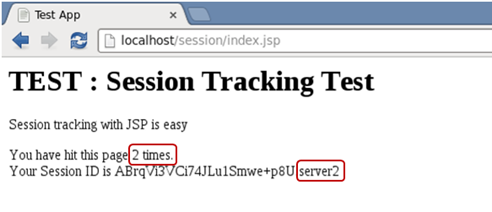
-
-
정지 상태인 1번 JBoss 인스턴스를 다시 실행
-
앞서 정지시켰던
server1JBoss 인스턴스를 실행한다. 이 단계는server2JBoss 인스턴스를 정지시키기 전에 상태 정보를 백업하기 위한 것이다.$ ./server1.sh
… 생략 …
17:23:23,141 INFO [org.jboss.as] (Controller Boot Thread) JBAS015961: Http management interface listening on http://127.0.0.1:9990/management
17:23:23,142 INFO [org.jboss.as] (Controller Boot Thread) JBAS015951: Admin console listening on http://127.0.0.1:9990
17:23:23,143 INFO [org.jboss.as] (Controller Boot Thread) JBAS015874: JBoss EAP 6.2.0.GA (AS 7.3.0.Final-redhat-14) started in 10619ms - Started 175 of 299 services (123 services are passive or on-demand)
-
-
2번 JBoss 인스턴스 정지
-
현재 세션이 생성되어 있는
server2JBoss 인스턴스를 정지한다.17:22:48,812 INFO [stdout] (ajp-/127.0.0.1:8109-3) session=ABrqVi3VCi74JLu1Smwe+p8U.server2
17:23:22,031 INFO [org.jboss.as.clustering] (Incoming-9,shared=udp) JBAS010225: New cluster view for partition web (id: 3, delta: 1, merge: false) : [server2/web, server1/web]
17:23:22,033 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-9,shared=udp) ISPN000094: Received new cluster view: [server2/web|3] [server2/web, server1/web]
^C
… 생략 …
17:25:09,232 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-2) ISPN000082: Stopping the RpcDispatcher
17:25:09,250 INFO [org.jboss.as] (MSC service thread 1-1) JBAS015950: JBoss EAP 6.2.0.GA (AS 7.3.0.Final-redhat-14) stopped in 545ms
-
-
3번째 요청 전송
-
웹 브라우저에서 3번째 요청을 보내면 세션에 저장된 값이 3으로 변경되고
server1으로 요청이 전달된다.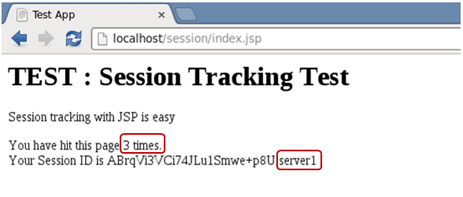
-
웹 브라우저에서 총 3번의 요청을 전송하였고 접속한 JBoss 인스턴스를 강제로 종료하였음에도 불구하고 세션에 저장된 카운트는 차례로 증가하여 3이 되었고, 세션 아이디는 같음을 확인할 수 있었다. 즉, JBoss 인스턴스의 장애 상황에서도 세션 정보가 정상적으로 유지되는 것을 확인할 수 있었다.
7.mod_cluster 커넥터
mod_cluster개요
JBoss HTTP 커넥터인 mod_cluster는 JBoss EAP의 지능형 부하 분산 솔루션이다. JBoss mod_cluster 커뮤니티 프로젝트에서 개발하고 있다. 전통적인 HTTP 기반 로��드 밸런서들의 단점을 보완하기 위해서 시작한 프로젝트이다.
mod_cluster는 mod_jk와 마찬가지로 웹 서버에서 클라이언트 요청을 JBoss 인스턴스로 포워딩하는 기능을 제공하는 HTTP기반 로드 밸런싱 모듈이다. mod_cluster는 Mod-Cluster Management Protocol(MCMP)라는 추가적인 채널을 제공하여 전통적인 로드 밸런서 모듈보다 좀 더 정교하고 안정적인 서비스를 제공하는 지능적인 HTTP 기반 로드 밸런서이다.
mod_jk와 같은 로드 밸런서는 웹 서버가 뒷 단의 JBoss 인스턴스들의 정보를 미리 알고 있어야 하지만, mod_cluster의 경우엔 JBoss 인스턴스를 증설할 때 기존의 웹 서버를 재시작하지 않아도 된다. mod_cluster의 동적 발견(Discovery)기능을 사용하기 때문이다. 새로운 노드를 추가하면 자동으로 웹 서버에 연동된다.
mod_cluster의 주요 특징
mod_cluster 커넥터는 여러 장점이 있다.
- Mod_Cluster Management Protocol(MCMP)는 JBoss 인스턴스와 웹 서버 사이의 연결 프로토콜이다. JBoss 인스턴스의 부하분산 요소와 생명 주기 이벤트를 웹 서버로 전송한다.
- JBoss 인스턴스를 추가할 때 웹 서버의 설정을 변경하지 않아도 된다.
- 애플리케이션 서버는 부하 분산 요소(factor)의 계산이 다른 커넥터보다 정확하다.
mod_cluster통해 애플리케이션 생명 주기를 제어할 수 있다. 웹 서버는 JBoss 인스턴스에 배포된 웹 애플리케이션 컨텍스트 정보를 알 수 있다. 즉, 애플리케이션이 배포된 JBoss 인스턴스에만 요청을 포워딩할 수 있기 때문에, 서버 중지나 애플리케이션 배포시 사용자에게 404 오류가 출력되지 않는다.- HTTP, HTTPS, AJP등 다양한 프로토콜로 포워딩할 수 있다.
mod_cluster 구성 및 설치
mod_cluster를 웹 서버와 JBoss에 설정하는 방법을 살펴보자.
작업 절차
따라하기
- 웹 서버 커넥터 다운로드
- HTTPD 모듈 디렉터리에
*.so파일 복사mod_cluster.conf파일 작성httpd.conf수정- 웹 서버 시작
standalone-ha.xml파일에서multicast-address변경- JBoss EAP 인스턴스 실행
mod_cluster_manager에서 연결상태 확인
-
웹 서버 커넥터 다운로드
-
레드햇 고객 포탈(http://access.redhat.com)에 접속하여 설치할 OS 플랫폼에 맞는 JBoss EAP 6 의 웹 서버 커넥터 네이티브 패키지를 다운로드한다.

-
-
HTTPD 모듈 디렉터리에
*.so파일 복사-
다운로드한 웹 커넥터 네이티브 패키지 압축을 푼다.
$ cd /EAP6book/jboss
$ unzip ~/Downloads/jboss-eap-native-webserver-connectors-6.2.0-RHEL6-x86_64.zip
Archive: /home/admin/Downloads/jboss-eap-native-webserver-connectors-6.2.0-RHEL6-x86_64.zip
creating: jboss-eap-6.2/modules/system/layers/base/native/
creating: jboss-eap-6.2/modules/system/layers/base/native/etc/
… 생략 …
creating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_jk.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_manager.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_advertise.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_proxy_cluster.so
inflating: jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/mod_slotmem.so
inflating: jboss-eap-6.2/SHA256SUM -
*.so파일을$HTTPD_HOME/modules/디렉터리로 복사한다.$ cd /EAP6book/jboss/jboss-eap-6.2/modules/system/layers/base/native/lib64/httpd/modules/
$ cp *.so /EAP6book/web/jboss-ews-2.0/httpd/modules/
-
-
mod_cluster.conf파일 작성jboss-eap-native-webserver-connectors-6.2.0-RHEL6-x86_64.zip파일 내의jboss-eap-6.2/modules/system/layers/base/native/etc/httpd/conf내의mod_cluster.conf를 참조하여 Apache HTTP서버가 설치된 디렉터리의conf.d디렉터리($HTTPD_HOME/conf.d) 에mod_cluster.conf파일을 작성한다.# mod_proxy_balancer should be disabled when mod_cluster is used
LoadModule proxy_cluster_module modules/mod_proxy_cluster.so
LoadModule slotmem_module modules/mod_slotmem.so
LoadModule manager_module modules/mod_manager.so
LoadModule advertise_module modules/mod_advertise.so
MemManagerFile /var/cache/mod_cluster
<IfModule manager_module>
Listen 6666
<VirtualHost 127.0.0.1:6666>
<Directory />
Order deny,allow
Allow from all
</Directory>
ServerAdvertise on
AdvertiseGroup 224.0.1.105:23364
EnableMCPMReceive
ErrorLog logs/modcluster.log
LogLevel info
<Location /mod_cluster_manager>
SetHandler mod_cluster-manager
Order deny,allow
Allow from all
</Location>
</VirtualHost>
</IfModule>
NameVirtualHost *:80
<VirtualHost *:80>
ProxyPass /* balancer://mycluster/* stickysession=JSESSIONID|jsessionid nofailover=On
ProxyPassMatch ^/.*\.(jsp|do|mvc)$ balancer://mycluster/
<Location />
Order Deny,Allow
Allow from All
</Location>
<Location /mod_cluster_manager>
SetHandler mod_cluster-manager
Order deny,allow
Allow from all
</Location>
</VirtualHost>- 앞 절에서 설정한
mod_jk.conf파일이 있으면,mod_jk.conf.bak으로 이름을 변��경한다.
- 앞 절에서 설정한
-
httpd.conf수정-
conf디렉터리로 이동한다.$ cd $HTTPD_HOME/conf*
$ vi httpd.conf* -
httpd.conf파일의proxy_balancer_module을 사용하지 않도록 주석 처리되어 있는지 확인한다.##LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
-
-
웹 서버 시작
mod_cluster.conf파일을 작성한 후 웹 서버를 시작한다.$ cd $HTTPD_HOME/sbin
$ sudo ./apachectl stop
$ sudo ./apachectl start -
standalone-ha.xml파일에서multicast-address변경- 다른 클러스터와 충돌을 피하려고
standalone-ha.xml을 수정하여 기존 멀티캐스트 주소를 변경한다.modcluster소켓 바인딩에서${변수명:기본값}형식을 사용할 수 있도록 다음과 같이 변경한다.server1,server2의standalone-ha.xml파일을 모두 변경한다.
- 다른 클러스터와 충돌을 피하려고
<socket-binding name="modcluster" port="0" multicast-address="${jboss.modcluster.multicast.address:224.0.1.105}" multicast-port="23364"/>
mod_cluster 멀티캐스트 주소를 변경하려면 server1.sh, server2.sh 파일에 -Djboss.modcluster.multicast.address=224.10.1.1와 같이 파라미터를 추가하면 된다. 같은 네트워크에 JBoss EAP 6 인스턴스가 있으면 이 설정을 꼭 사용해야 한다.
-
JBoss EAP 인스턴스 실행
-
첫 번째 JBoss 인스턴스 실행 –
port-offset=0$ cd $JBOSS_HOME/server1
$ ./server1.sh -
두 번째 JBoss 인스턴스 실행–
port-offset=100$ cd $JBOSS_HOME/server2
$ ./server2.sh
-
-
mod_cluster_manager에서 연결상태 확인웹 브라우저에서
http://localhost/mod_cluster_manager에 접속하여mod_cluster를 이용한 연결상태를 확인한다.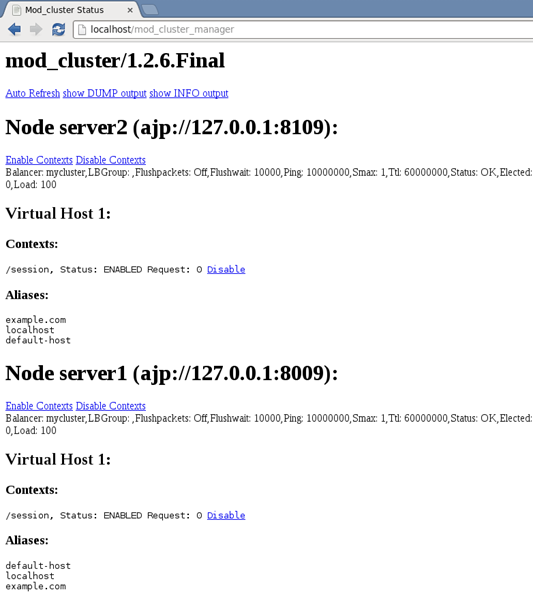
mod_cluster 컴포넌트
설정 예제에서 보면, mod_cluster.conf 파일에서 LoadModule을 사용하여 4개의 모듈을 설정했다. 각 모듈이 어떤 역할을 하는지 살펴보자.
| 모듈명 | 설명 |
|---|---|
| mod_slotmem.so | 공유 메모리 관리 모듈 : 공유 메모리를 사용하여 워커 노드 정보를 여러 웹 서버 프로세스에서 사용할 수 있도록 한다. |
| mod_manager.so | 클러스터 관리 모듈 : 워커 노드 등록과 워커 노드 부하 데이터, 애플리케이션 생명 주기 이벤트 등의 메시지를 수신하고 모니터링 한다. |
| mod_proxy_cluster.so | 프록시 밸란서 모듈 : 클러스터 노드로 요청을 라우팅한다. 클러스터내의 각 노드 애플리케이션의 현재 상태 정보, 세션 ID에 따라 요청을 전달할 노드를 선택하여 전달한다. |
| mod_advertise.so | 프록시 Advertisement 모듈 : UDP 멀티캐스트 메시지를 사용하여 프록시 서버의 상태를 브로드 캐스트 한다. JBoss EAP 인스턴스와 같은 멀티캐스트 IP를 사용하여 웹 서버와 JBoss 인스턴스 간의 상태 정보를 파악한다. |
표 . mod_cluster 구성 모듈
mod_manager.so
클러스터 관리 모듈인 mod_manager 는 워커 노드 등록하고 워커 노드의 부하상태에 대한 데이터, 애플리케이션 라이프 사이클 이벤트 등의 메시지를 수신한다.
LoadModule manager_module modules/mod_manager.so
mod_manager 모듈에서 설정할 수 있는 지시어는 다음과 같다. 웹 서버의 VirtualHost 지시어 안에서 사용한다.
| 구분 | 기본값 | 기본값 |
|---|---|---|
| MemManagerFile | /logs/ | mod_manager가 사용하는 파일을 저장하는 위치를 지정한다. 공유 메모리 사용을 위한 키나 락 파일이 이 위치에 저장된다. 절대 경로를 사용해야 한다. 공유 디렉터리를 사용하지 말고 로컬 디스크의 위치를 사용하는 것이 좋다. |
| Maxcontext | 100 | mod_cluster가 사용할 컨텍스트의 최댓값이다. |
| Maxnode | 20 | mod_cluster가 사용할 워커 노드의 최댓값이다. |
| Maxhost | 20 | mod_cluster가 사용할 호스트의 최댓값이다. 로드 밸런서 최대 개수이다. |
| Maxsessionid | 0 | 저장되는 세션 ID의 최댓값이다. 5분 이내에 세션에서 받은 정보가 없으면 세션이 활성화되어 있지 않다고 판단한다. 기본값은 0 으로 비활성화 상태이다. |
| ManagerBalancerName | mycluster | 워커 노드가 로드 밸런서의 이름을 지정하지 않은 경우에 사용하는 로드 밸런서의 이름이다. 기본값은 mycluster 이다. |
| PersistSlots | off | on으로 설정하면 노드 이름과 컨텍스트가 파일에 저장된다. |
| CheckNonce | on | on으로 설정하면 세션 ID가 이전에 사용된 적이 있는지 확인한다. |
| SetHandler | a | 핸들러를 정의하면 클러스터의 워커 노드에 대한 정보를 표시하는 웹 페이지를 사용할 수 있다. |
<Location /mod_cluster_manager>
SetHandler mod_cluster-manager
Order deny, allow
Deny from all
Allow from 127.0.0.1
</ Location>
표 . mod_manager 모듈의 지시어
mod_proxy_cluster.so
mod_proxy_cluster는 클러스터 노드에 요청을 라우팅한다. 클러스터내의 애플리케이션의 상태 정보, 세션 ID 등에 따라서 전달할 노드를 선택하고, 요청을 전달한다.
LoadModule proxy_cluster_module modules/mod_proxy_cluster.so
| 항목 | 기본값 | 설명 |
|---|---|---|
| CreateBalancers | 2 | 웹 서버의 가상 호스트에서 로드 밸런서를 만드는 방법을 정의한다. * 0 – 웹 서버에 정의된 모든 가상 호스트에 대해서 로드밸런서를 만든다. * 1 - 밸런서를 만들지 않는다. * 2 - 메인 서버만 만든다. 기본값이다. |
| UseAlias | 0 | 정의된 이름이 ServerName과 같은지 확인한다.. * 0 - 확인하지 않는다. 기본값이다. * 1 - 일치하는지 확인한다. |
| LBstatusRecalTime | 5 초 | 워커 노드의 상태를 계산하는 시간 간격을 정의한다. |
표 . mod_proxy_cluster의 부하 분산 관련 설정
ProxyPass
ProxyPass 는 원격 서버를 로컬 서버의 특정 주소에 맵핑하여 연결한다.
ProxyPass /requested/ http://worker.opennaru.com/
로컬 서버의 주소가 http://opennaru.com/ 을 가지고 있다면 위의 ProxyPass 지시문은 http://opennaru.com/requested/file1 의 로컬 요청을 http://worker.opennaru.com/file1 의 프록시 요청으로 변환하여 전달한다.
ProxyPass를 사용하여 JBoss EAP 인스턴스들에 요청을 전달하게 설정할 수 있다. 다음은 모든 요청을 mycluster라는 로드 밸런서로 전달하는 설정이다.
ProxyPass /* balancer://mycluster/*
백엔드 JBoss 인스턴스로 요청을 전달하지 말아야 할 경우에는 ‘!’을 사용한다. 다음은 정적인 컨텐츠가 보관된 images, js, css 디렉터리 하위의 요청을 전달하지 않도록 설정한 것이다.
ProxyPass /images !
ProxyPass /js !
ProxyPass /css !
특정 하위 디렉터리를 리버스 프록시하고 싶지 않을 때 ‘!’을 사용할 수 있다. 예를 들어, 다음의 설정은 /mirror/foo/i 를 제외한 /mirror/foo 요청을 backend.opennaru.com 에 전달한다.
ProxyPass /mirror/foo/i !
ProxyPass /mirror/foo http://backend.opennaru.com
ProxyPassMatch;
ProxyPassMatch는 정규식을 사용하여 프록시 URL 패턴을 지정할 때 사용한다.
단순한 문자열 비교가 아닌 정규식을 사용하는 것을 제외하고 ProxyPass 와 같다.
ProxyPassMatch ^(/*\.gif)$ http://backend.opennaru.com/$1
http://opennaru.com/foo/bar.gif 에 대한 요청을 내부적으로 http://backend.opennaru.com/foo/bar.gif 프록시 요청으로 변환하여 전달한다.
마찬가지로 특정 확장자 패턴에 대해서 JBoss 인스턴스로 전달하지 않도록 다음과 같이 설정할 수 있다.
ProxyPassMatch ^(/.*\.xml)$ !
ProxyPassMatch ^(/.*\.swf)$ !
mod_advertise.so
mod_advertise는 UDP 멀티캐스트 메시지를 사용하여 JBoss EAP 인스턴스와 웹 서버간의 상태를 브로드 캐스트한다. 클러스터링 멤버로 참가하고, 떠나는 것과 같은 상태 정보를 서로 알 수 있도록 설정한다.
LoadModule advertise_module modules/mod_advertise.so
| 구분 | 기본값 | 기본값 |
|---|---|---|
| ServerAdvertise | Advertise하는 메커니즘을 정의한다.\n * On으로 설정하면, 멀티캐스트�를 사용하여 워커 노드에 프록시 상태 정보를 보낸다. * ServerAdvertise On http://hostname:port/ 에서 호스트 이름과 포트를 지정할 수 있다. 이름 기반의 가상 호스트를 사용하거나 가상 호스트를 사용하지 않는 경우에 지정한다. | Off |
| AdvertiseGroup | 멀티캐스트 주소를 정의한다. * AdvertiseGroup_주소:포트로 설정한다. * JBoss EAP의 mod_cluster가 사용하는 멀티캐스트 IP, 포트와 같은 값을 지정한다. | 224.0.1.105:23364 |
| AdvertiseFrequency | 멀티캐스트 메시지 전송 간격을 설정한다. | 10초 |
| AdvertiseSecurityKey | JBoss EAP의 mod_cluster를 식별하는 데 사용하는 문자열을 지정한다. | |
| AdvertiseBindAddress | 멀티캐스트 메시지를 보낼 때 사용할 바인드 주소를 정의한다. NIC가 여러 개 있을 경우 특정 IP 주소가 Advertise멀티캐스트 메시지를 사용하도록 설정할 수 있다. 기본값은 0.0.0.0:23364 이다. |
표 . mod_advertise 설정 항목
mod_cluster 서브시스템 설정
웹 관리 콘솔에서 ‘Profile’ ‘Web’ ‘mod_cluster’에서 mod_cluster 서브 시스템을 설정할 수 있다. 기본적으로 ha 프로파일과 full-ha 프로파일에만 mod_cluster 서브 시스템이 활성화된다. 스탠드얼론 서버는 standalone-ha.xml 을 사용하여 서버를 시작해야 한다. 밸란서의 이름이나, 세션, 웹 컨텍스트, 프록시, SSL 및 네트워킹을 설정할 수 있다.

그림 8. mod_cluster 서브시스템 설정 화면
웹 컨텍스트 설정에서는 JBoss EAP 6 내부적으로 사용하는 컨텍스트들에 대해서 mod_cluster에 전달되지 않도록 설정되어 있다. 이 컨텍스트에 루트 컨텍스트(ROOT)가 포함되어 있어, 애플리케이션에서 루트 컨텍스트를 사용하려면 다음과 같이 ROOT 컨텍스트를 사용하도록 변경하여야 한다.
[standalone@localhost:9999 /] /subsystem=modcluster/mod-cluster-config=configuration:write-attribute(name="excluded-contexts",value="invoker,jbossws,juddi,console")
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
기본적으로 스티키 세션을 사용하도록 설정되어 있다.
mod_cluster 스티키 세션
스티키 세션을 사용하려면 JBoss EAP 뿐만 아니라 웹 서버의 mod_cluster 설정도 필요하다. 다음과 같이 ProxyPass에서 stickysession을 다음과 같이 설정한다.
ProxyPass /* balancer://mycluster/* *stickysession=JSESSIONID|jsessionid nofailover=On*
ProxyPassMatch ^/.*\.(jsp|do|mvc)$ balancer://mycluster/
8.EJB 애플리케이션 클러스터
EJB 애플리케이션에서도 클러스터링에서 필요한 로드 밸런싱, 세션 복제, 장애 복구기능을 모두 제공한다. 다음은 EJB 애플리케이션을 클러스터링 구성했을 경우, 클라이언트와 호출을 나타낸 �그림이다.

그림 9. JBoss EAP 6의 EJB 클러스터링
다음의 표. 10은 Stateful세션 빈(SFSB)과 Stateless 세션 빈(SLSB)의 클러스터링 기능을 정리한 것이다.
Stateless 세션 빈은 상태를 가지지 않기 때문에 복제할 세션이 없다. Stateful 세션 빈의 경우, 로드 밸런싱 기능과 세션을 복제하여 클러스터링을 구성한다.
| 세션 빈 종류 | 로드밸런싱 | 세션 복제 | 장애 복구 |
|---|---|---|---|
| Stateful세션 빈 | O | O | O |
| Stateless 세션 빈 | O | X | O |
표 11. Stateful세션 빈과 Stateless 세션 빈의 클러스터링 기능 비교
-
로드밸런싱 EJB 애플리케이션에 대한 로드 밸런싱은 EJB 클라이언트의 라이브러리에서 제공한다.
-
세션 복제 ‘EJB 세션 복제’는 웹 세션 복제와 마찬가지로 SFSB의 상태를 다른 서버에 복사해 놓는 기능이다. 상태를 복제해 놓았기 때문에, 특정 서버 노드가 정지했을 경우에도 상태를 잃지 않고, SFSB을 계속 처리할 수 있다.
-
장애 복구 EJB 애플리케이션의 장애 복구는 EJB 애플리케이션 실행 중 서버에 장애가 발생했을 때, 다른 서버 노드가 처리를 계속하는 기능이다. 이 기능은 EJB 클라이언트와 세션 복제 기능(SFSB)으로 제공한다. EJB 클라이언트는 서버 노드의 장애를 감지하면, 접속하고 있는 클러스터내의 다른 서버 노드에서 수행 중이던 처리를 다시 실행한다.
EJB 클러스터링 테스트
다음에서는 실제 EJB 애플리케이션의 클러스터 환경 구축과 리모트 호출 방법을 설명한다.
EJB 애플리케이션 클러스터 환경 구축
EJB 애플리케이션 클러스터링을 구성하려면 웹 클러스터링과 마찬가지로 ha, full-ha 프로파일을 사용하면 된다. 스탠드얼론 서버의 경우엔 standalone-ha.xml, standalone-full-ha.xml을 사용한다.
웹 애플리케이션과 같이 ha 프로파일에 미리 EJB 세션 복제 설정이 되어 있기 때문에, 같은 설정의 JBoss EAP 6 인스턴스를 여러 개 실행하면, 자동으로 감지해 클러스터를 구성한다. 로드 밸런싱만을 사용하고 싶어도 서버 측에 클러스터를 구성해야 한다. EJB 클라이언트에서 원격의 EJB를 로드밸런싱할 때, 클러스터에 있는 서버리스트를 받아서 호출하기 때문이다.
Stateful 세션 빈 개발
Stateful 세션 빈 구현할 때 세션을 복제하고 싶은 클래스에 @Clustered 어노테이션(org.jboss.ejb3.annotation.Clustered)을 기술한다. 다음은 구현 예제이다. 이제 EJB 개발이 정말 쉬워졌다.
package com.opennaru.ejb;
import javax.ejb.Remote;
import javax.ejb.Stateful;
import org.jboss.ejb3.annotation.Clustered;
@Stateful
@Clustered
@Remote(IHello.class)
public class Hello implements IHello {
private int counter = 0;
public String doSomething() {
return ("Hello EJB3 called : " + (++counter) );
}
}
@Clustered 어노테이션을 사용하려면 메이븐 pom.xml파일에 jboss-ejb3-ext-api을 추가하여 컴파일 해야 한다.
<dependency>
<groupId>org.jboss.ejb3</groupId>
<artifactId>jboss-ejb3-ext-api</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
@Clustered 어노테이션을 기술한 클래스를 JBoss에 배포하면, JBoss는 자동으로 세션 복제 대상 클래스를 찾아 세션을 다른 서버 노드에 복제한다.
다음은 server1를 시작 후 server2를 기동시켰을 경우의 로그이다.
22:09:27,250 INFO [stdout] (ServerService Thread Pool -- 61) -------------------------------------------------------------------
22:09:27,250 INFO [stdout] (ServerService Thread Pool -- 61) GMS: address=server1/ejb, cluster=ejb, physical address=192.168.0.28:55200
22:09:27,250 INFO [stdout] (ServerService Thread Pool -- 61) -------------------------------------------------------------------
22:09:29,253 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (ServerService Thread Pool -- 61) ISPN000094: Received new cluster view: [server1/ejb|0] [server1/ejb]
22:09:29,331 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (ServerService Thread Pool -- 61) ISPN000079: Cache local address is server1/ejb, physical addresses are [192.168.0.28:55200]
… 중략 …
22:09:29,481 INFO [org.jboss.web] (ServerService Thread Pool -- 61) JBAS018210: Register web context: /helloejb
22:09:29,536 INFO [org.jboss.as.server] (HttpManagementService-threads - 1) JBAS018559: Deployed "helloejb.war" (runtime-name : "helloejb.war")
22:09:47,856 INFO [org.jboss.as.clustering] (Incoming-3,shared=udp) JBAS010225: *New cluster view for partition ejb (id: 1, delta: 1, merge: false) : [server1/ejb, server2/ejb]*
22:09:47,860 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-3,shared=udp) ISPN000094: *Received new cluster view: [server1/ejb|1] [server1/ejb, server2/ejb]*
리모트 호출 처리의 구현
InitialContext를 초기화해 lookup한 후, 리모트 EJB를 호출한다. 호출하는 클라이언트 코드는 다음과 같다.
package com.opennaru.ejb;
import java.util.Properties;
import javax.naming.Context;
import javax.naming.InitialContext;
public class HelloClient {
public static void main(String[] args) throws Exception {
Properties p = new Properties();
p.put(Context.URL_PKG_PREFIXES, "org.jboss.ejb.client.naming");
InitialContext ctx = new InitialContext(p);
IHello ejb = (IHello) ctx.lookup("ejb:/helloejb/Hello!" + IHello.class.getName() + "?stateful");
for (int i = 0; i < 10; i++) {
System.out.println( ejb.doSomething() );
}
}
}
InitialContext의 초기화에 사용할 프로퍼티 파일에 클러스터 환경용 설정을 추가하여야 한다. 다��음은 jboss-ejb-client.properties의 설정 예이다.
remote.connectionprovider.create.options.org.xnio.Options.SSL_ENABLED=false
remote.connections=server1,server2
remote.connection.server1.host=192.168.0.101
remote.connection.server1.port=4447
remote.connection.server1.connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS=false
remote.connection.server1.username=admin
remote.connection.server1.password=opennaru!234
remote.connection.server2.host=192.168.0.101
remote.connection.server2.port=4547
remote.connection.server2.connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS=false
remote.connection.server2.username=admin
remote.connection.server2.password= opennaru!234
원격의 서버리스트를 remote.connections에서 server1, server2로 정의하였고, 해당 서버에 대한 정보를 프로퍼티 파일 안에서 server1, server2에 대한 IP, 포트를 설정하였다.
JBoss EAP 6에서 EJB 애플리케이션 배포를 위한 클러스터링 환경 구축, 구현 및 리모트 호출 방법에 대해 살펴보았다.
9.JMS 클러스터링
JBoss EAP 6의 JMS 프로바이더인 HornetQ는 클러스터링 기능과 고가용성 기능(HA)이 따로 제공되고 있다. 각각의 기능을 조합하여, 다양한 클러스터 구성이 가능하게 되었다.
HornetQ 클�러스터링
HornetQ는 로드 밸런싱 기능과 HornetQ 서버로 클러스터 그룹을 구성하여 클러스터링 기능을 제공한다.
HornetQ의 로드 밸런싱은, 서버와 클라이언트에서 로드 밸런싱이 가능하다.
서버의 로드 밸런싱은 메시지 프로듀서에서 메시지 수신 시 클러스터에 포함된 다른 노드에 라운드 로빈으로 전달하여 부하를 분산한다. 다만, 로드 밸런서가 메시지를 다른 노드에 전달하여 분배하였지만, 노드에 메시지 컨슈머가 없을 때는 메시지를 큐(Queue)에 보관한다. 이렇게 보관된 메시지를 처리하기 위해, 메시지 컨슈머가 있는 다른 클러스터 노드에 메시지를 재분배할 수도 있다.
클라이언트에서의 로드 밸런싱은 클라이언트의 접속 팩토리(ConnectionFactory)에서 만들어지는 Connection에서 클러스터에 포함된 서버들의 정보를 얻는다. 클라이언트는 서버 중 대상을 선택하여 메시지를 분산하는 방식이다. 클라이언트는 서버를 선택하는 로드 밸런싱 정책을 바꿀 수 있고, 라운드로빈(기본값)과 랜덤 방식을 사용할 수 있다.
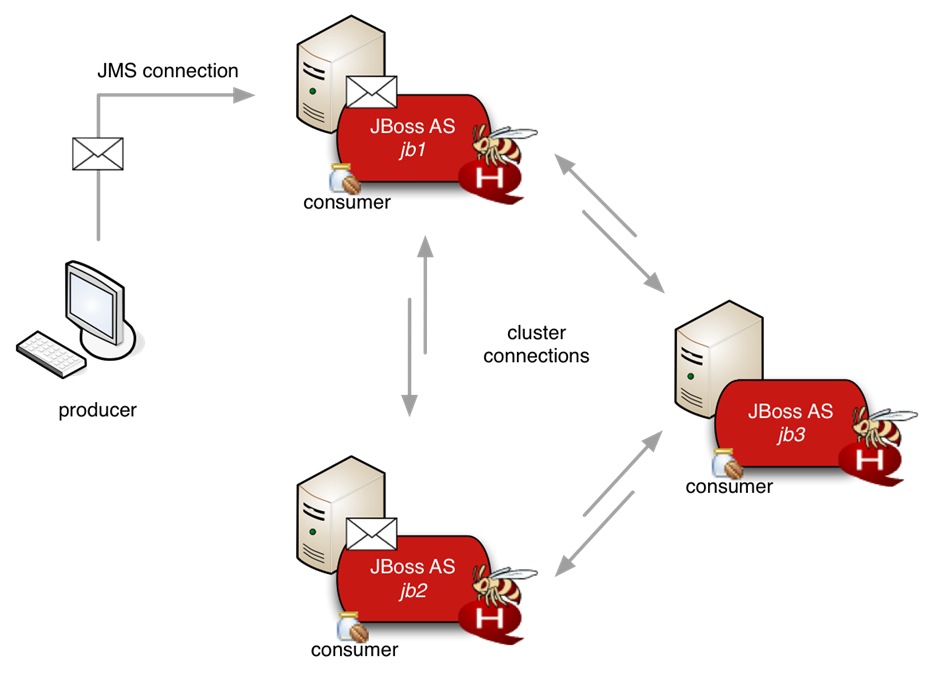
그림 10. HornetQ 클러스터링 구성
JMS기능은 full 프로파일에서 제공한다. 또 클러스터링 기능은 ha 프로파일에서 제공한다. 따라서 JMS의 클러스터링 기능을 사용하기 위해서는 full-ha 프로파일을 사용하여야만 한다. 스탠드얼론 모드에서는 standalone-full-ha.xml 설정 파일을 사용하여 서버를 시작한다.
$./standalone.sh --server-config=standalone-full-ha.xml
이번에 설명하는 클러스터링 구성은 다음 그림과 같다. JBoss EAP 6 인스턴스에 JMS기능을 제공하는 HornetQ가 각각 동작하고 있고, 각각의 HornetQ 서버는 로컬 디스크에 메시지를 저장한다. 앞서 메시징 서브시스템에서 설명한 것과 같이 리눅스 운영체제를 사용하는 경우는 Journal파일에 기록하는 성능을 향상하기 위해 AIO를 사용하도록 설정하는 것이 좋다.
그림11. HornetQ 클러스터링 구성
클러스터링 설정
full-ha 프로파일에서 클러스터링 기능은 clustered 속성으로 설정되어 있다.
설정 값은 다음의 CLI 명령으로 확인할 수 있다.
[standalone@localhost:9999 /] cd /subsystem=messaging/hornetq-server=default
[standalone@localhost:9999 hornetq-server=default] :read-attribute(name=clustered)
{
"outcome" => "success",
"result" => true
}
클러스터링하지 않으려면 다음 CLI 명령을 실행한다.
[standalone@localhost:9999 /] cd /subsystem=messaging/hornetq-server=default
[standalone@localhost:9999 hornetq-server=default] :write-attribute(name=clustered, value=false)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
클러스터를 사용하려면 먼저 cluster-password를 설정하여야 한다. 다음 CLI 명령을 사용하여 클러스터 패스워드를 설정한다. JBoss EAP 6를 설치할 때 사용했던, 관리자 패스워드를 입력한다.
따라하기
- CLI로HornetQ로 이동
- 패스워드 설정
- 리로드
- 설정값 확인
- CLI로HornetQ로 이동
[standalone@localhost:9999 /] cd /subsystem=messaging/hornetq-server=default
-
패스워드 설정
[standalone@localhost:9999 hornetq-server=default] :write-attribute(name=cluster-password, value=opennaru!234)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
} -
리로드
[standalone@localhost:9999 /] /:reload
- 설정값 확인
[standalone@localhost:9999 hornetq-server=default] :read-attribute(name=cluster-password)
{
"outcome" => "success",
"result" => "opennaru!234"
}
클러스터링 구성 확인
클러스터링이 정상적으로 구성되어 있는지를 CLI를 이용해 확인할 수 있다. 모든 노드를 시작하여, cluster-connection의 topology 파라미터를 참조하여 클러스터링을 구성하고 있는 멤버를 확인할 수 있다.
다음의 설정을 확인 방법에 대해 설명한다.
full-ha프로파일을 사용하는 2개의 노드(192.168.10.22,192.168.10.23)- 각각의 노드에 1개의 HornetQ 서버
cluster-connection은my-cluster(기본값)
따라하기
- CLI로 HornetQ로 이동
cluster-connection에 이동- 클러스터
connection의 topology를 확인(:read-attribute)
- CLI로 HornetQ로 이동
[standalone@localhost:9999 /] cd /subsystem=messaging/hornetq-server=default
cluster-connection에 이동
[standalone@localhost:9999 hornetq-server=default] cd cluster-connection=my-cluster
- 클러스터
connection의 topology를 확인(:read-attribute)[standalone@localhost:9999 cluster-connection=my-cluster] :read-attribute(name=topology)
{
"outcome" => "success",
"result" => "topology on Topology@1b7b162[owner=ClusterConnectionImpl@4593540[nodeUUID=238320de-5aea-11e3-b75b-0b74fc5badf6, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=192-168-0-22, address=jms, server=HornetQServerImpl::serverUUID=238320de-5aea-11e3-b75b-0b74fc5badf6]]:
238320de-5aea-11e3-b75b-0b74fc5badf6 => TopologyMember[name = undefined, connector=Pair[a=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory)?port=5645&host=192-168-0-22, b=null]]
632b962a-5739-11e3-b2f9-73f77b88aeca => TopologyMember[name = undefined, connector=Pair[a=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory)?port=5545&host=192-168-0-23, b=null]]
nodes=2 members=2"
}
클러스터 연결 정보가 다음 형식으로 출력된다.
topology on Topology@1b7b162[owner=ClusterConnectionImpl@4593540[nodeUUID=238320de-5aea-11e3-b75b-0b74fc5badf6, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=192-168-0-22, address=jms, server=HornetQServerImpl::serverUUID=238320de-5aea-11e3-b75b-0b74fc5badf6]]:
두 번째 라인부터 클러스터에 참가하고 있는 노드의 정보가 출력된다.
238320de-5aea-11e3-b75b-0b74fc5badf6 => TopologyMember[name = undefined, connector=Pair[a=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory)?port=5645&host=192-168-0-22, b=null]]
여기서 a=TransportConfiguration…, b=null 형식으로 출력되는 데 a를 라이브 서버 정보, b는 백업 서버 정보를 나타낸다.
맨 마지막에 HornetQ 클러스터를 구성하고 있는 멤버 수를 표시한다. 여기서는 HornetQ 서버 수(nodes)는 2, 클러스터를 구성하고 있는 멤버 수(members)는 2개 이다.
**nodes=2 members=2"**
라이브-백업 클러스터 구성
HornetQ는 엔터프라이즈 환경에서는 반드시 필요한 신뢰성을 구현하기 위해서 라이브-백업 구성으로 클러스터링을 ��구성할 수 있다. 라이브 서버는 JMS 서버로서의 실제 서비스를 제공하는 서버이다. 백업 서버는 사용되지 않고 있다가 라이브 서버에 장애가 발생할 때 사용되는 대기 상태의 서버이다. 장애 복구가 발생하면 백업 서버가 액티브 되어, 라이브 서버 대신 JMS 서버의 기능을 제공한다. 장애 복구가 발생하는 조건은 다음과 같다.
- 액티브한 라이브 서버 크래쉬
- 셧다운(셧다운을 장애 복구가 발생 시점으로 설정했을 경우)
또, 장애 복구가 발생 후, 라이브 서버를 재기동하면, 다시 원래 라이브 서버가 서비스하고 백업 서버는 대기 상태가 되는 Fail-back기능도 제공한다. HornetQ에서는 라이브 - 백업 구성 방식으로 데이터 복제와 공유 스토어를 사용하는 2가지 방식의 모드를 제공한다.
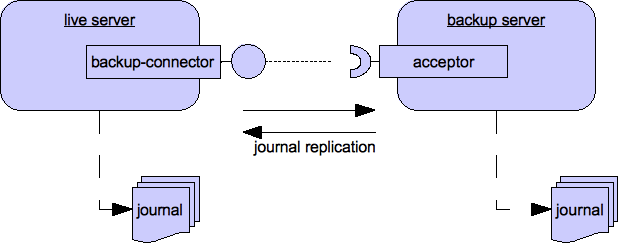
그림 12. 데이터 복제 모드
데이터 복제 모드에서는 네트워크를 통해 라이브 서버의 데이터를 백업 서버로 복제한다. 백업 서버를 시작할 때 라이브서버의 모든 데이터를 동기화해야 한다. 동기화 중에 라이브서버가 장애가 발생하면, 백업서버는 라이브 서버를 대체할 수 없게 된다.
이런 데이터 복제가 필요 없는 방식이 공유 스토어 모드이다. 라이브 서버와 백업 서버가 같은 저장소(저널 파일 시스템)를 공유하는 방식이다. 장애 시 백업 서버는 라이브 서버 대신에 JMS 서버 기능을 제공하기 위해서 공유 파일 시스템상에 저널을 그래도 사용한다. 이 방식에서는 서로 다른 서버 간에 파일 시스템을 공유할 수 있는 SAN(Storage Area Network)과 같은 공유 디바이스가 필요하다.
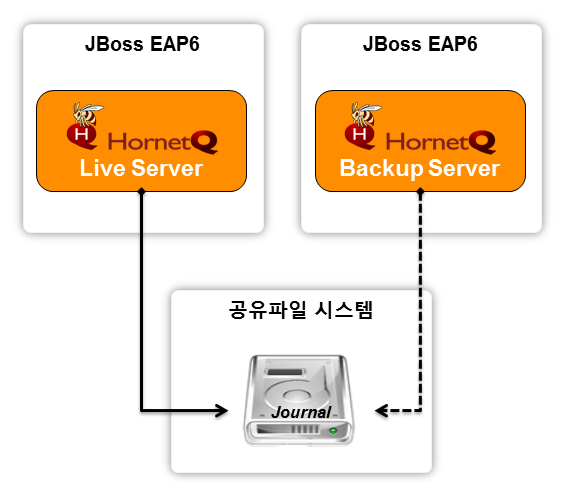
그림 13. 공유 스토어 모드
NFS(Network File System)등의 NAS(Network Attached Storage)는 데이터 전송 성능 문제가 있을 수 있어 추천하지 않는다. 또, 리눅스의 AIO를 사용할 경우, NFS에서 공유 스토어 모드는 정상적으로 동작하지 않는다.
또, HornetQ는 클라이언트 코드에서 자동 장애 복구 방법도 제공한다. 클라이언트 자동 장애 복구는 라이브 서버에서 장애가 발생해 액티브하게 된 백업 서버로 자동으로 재접속하여 실행 중이던 세션과 메시지 컨슈머를 자동으로 재작성해 처리하는 기능이다. 애플리케이션에서 장애시 재접속 방법을 직접 코딩할 필요가 없다.
10.클러스터 그룹
JBoss EAP 6에서는 하나의 물리 네트워크 내에 여러 클러스터 그룹을 구성할 수 있다. 지금까지 설명은 기본적으로 네트워크 내에 있는 전체 서버 노드를 하나의 클러스터로 구성하는 것을 전제로 설명했다. 클러스터 그룹이란 같은 서비스를 제공하는 서버 노드들을 묶어서 네트워크 내에 여러 클러스터를 구축하는 방법이다. 웹 애플리케이션, EJB 애플리케이션, JMS 각각의 클러스터링에 대해 설명했지만, 클러스터 그룹에 대해서도 각각 애플리케이션 단위 또는 서버 노드 단위로 구성할 수 있다.
웹, EJB 애플리케이션의 클러스터링을 위해서는 Infinispan와 JGroups 컴포넌트를 이용한다. 한편, JMS에서는 HornetQ 자체가 클러스터링 기능을 가지고 있다. 이 때문에 클러스터 그룹의 설정 방법도 다르다. 그래서 웹, EJB와 JMS를 나누어 설명한다.
웹, EJB 컨테이너 클러스터 그룹
웹, EJB 컨테이너는 클러스터링을 설정하는 서버 노드 간의 임의의 서버 노드에 대해서만 그룹을 구성할 수 있다. 다음 그림을 보면, 클러스터 그룹 A와 B를 구성하고 있다.
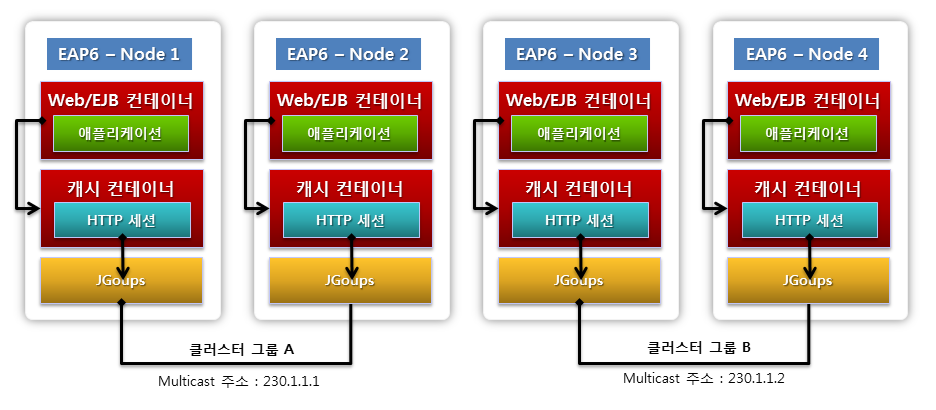
그림 14. 웹/EJB 컨테이너의 클러스터 그룹
웹, EJB클러스터 그룹 분할 방법
웹, EJB 애플리케이션은 클러스터링을 설정하기 위한 도구로 Infinispan와 JGroups라는 컴포넌트를 사용하고 있다. 클러스터 그룹을 분할하려면 Infinispan 또는 JGroups의 설정을 변경하여야 한다.
클러스터 노드 간 통신에 사용하는 JGroups는 데이터 전송 프로토콜은 UDP 멀티캐스트나 TCP를 사용할 수 있다. 기본적으로 UDP 멀티캐스트를 사용하기 때문에 네트워크를 나누려면 멀티캐스트 주소를 변경하면 된다.
JBoss EAP 6의 시스템 프로퍼티 jboss.default.multicast.address 를 변경하여 논리적으로 네트워크를 분리할 수 있다. 멀티캐스트 주소 기본값은 230.0.0.4이다.
따라하기
jboss.default.multicast.address확인jboss.default.multicast.address를 시작 옵션으로 변경
jboss.default.multicast.address확인
[standalone@localhost:9999 /] cd /socket-binding-group=standard-sockets/socket-binding=jgroups-udp
[standalone@localhost:9999 socket-binding=jgroups-udp/] :read-resource
{
"outcome" => "success",
"result" => {
"client-mappings" => undefined,
"fixed-port" => false,
"interface" => undefined,
"multicast-address" => expression "${jboss.default.multicast.address:230. 0.0. 4}",
"multicast-port" => 45688,
"name" => "jgroups-udp",
"port" => 55200
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
-
jboss.default.multicast.address를 시작 옵션으로 변경-u옵션이나 시스템 프로퍼티를 사용하여 변경할 수 있다.$ ./standalone.sh -u=230.10.0.5 -c=standalone-ha.xml
$ ./standalone.sh -Djboss.default.multicast.address=230.10.0.5 -c=standalone-ha.xml
HornetQ 클러스터 그룹
HornetQ에서는 클러스터링을 구성하는 노드 그룹을 구성하여 여러 클러스터 그룹을 구성할 수 있다. 클러스터링을 구성하는 목적지(Queue/Topic)도 주소 단위로 지정할 수 있고, 주소마다 다른 클러스터링 그룹을 지정할 수도 있다. 하나의 JMS 서버가 여러 클러스터 그룹에 동시에 참가할 수 있어 다양한 클러스터 토폴로지를 구성하는 것이 가능하다.
HornetQ는 클러스터 그룹 구성을 쉽게 할 수 있도록 멀티캐스트를 사용하고 있다.
JBoss EAP 6의 JMS 기능을 제공하는 full 프로파일 중에서 JMS 클러스터링을 사용하려면 full-ha 프로파일을 사용하여야 한다. 스탠드얼론 모드에서는 standalone-full-ha.xml 를 사용한다. full-ha 프로파일에 클러스터 그룹을 구성하기 위한 설정이 이미 정의되어 있다. 소켓 바인딩에 설정된 JMS가 사용하는 UDP 멀티캐스트 주소와 포트를 사용하여 클러스터 그룹을 구성한다.
| 항목 | 설명 | 기본 설정값 |
|---|---|---|
multicast-address | 소켓이 멀티캐스트의 트래픽을 송수신할 때 사용하는 멀티캐스트 주소. | ${jboss.messaging.group.address:231.7.7.7} |
multicast-port | 소켓이 멀티캐스트 트래픽을 송수신할 때 사용하는 포트. | ${jboss.messaging.group.port:9876} |
표 1. JMS에서 사용하는 소켓바인딩 설정
JBoss EAP 6를 시작하면 동일 네트워크 내에 있는 HornetQ 서버는 소켓 바인딩의 UDP 멀티캐스트 주소와 포트를 사용하여 자동으로 클러스터 그룹을 구성한다. 기본 설정으로도 클러스터링 기능을 사용할 수 있도록 충분히 설정되어 있다.
-
클러스터 그룹 분할
HornetQ의 클러스터 그룹 분할 방법도 웹 컨테이너와 마찬가지로 사용하는 논리적으로 네트워크를 나누어 클러스터 그룹을 나누는 방법은 그룹마다 멀티캐스트 주소와 포트를 변경하는 방법이다. JBoss EAP 6 시작 인수로 지정하여 간단하게 변경할 수 있다.
서버시작 시 시스템 파라미터
jboss.messaging,group.address와jboss.messaging.group.port를 사용하여 멀티캐스트 그룹을 분리한다. 보통 멀티캐스트 주소만 변경하여 관리한다.
$ ./standalone.sh -c=standalone-full-ha.xml -Djboss.messaging.group.address=231.7.7.8 -Djboss.messaging.group.port=9877
11.Infinispan
JBoss EAP 6에서는 웹 애플리케이션, EJB 애플리케이션의 클러스터링 기능을 제공하기 위하여 먼저 소개한 JGroups와 Infinispan라는 프로젝트를 내부에서 사용하고 있다.
Infinispan는 JBoss Cache 후속 프로젝트로 개발이 진행되고 있고 ‘JBoss Data Grid Platform’이라는 별도의 제품으로 판매되고 있다. JBoss EAP 6에도 클러스터링을 구현하기 위해서 Infinispan을 사용하고 있지만, 애플리케이션에서 Infinispan의 API를 직접 이용하는 경우에 대해서는 기술지원을 하지 않는다. 클러스터링 기능을 변경하려면 Infinispan의 캐시 컨테이너 설정을 변경한다.
JBoss EAP 6의 웹 애플리케이션 및 EJB 애플리케이션에서 캐시 데이터 복제 모드는 전체 노드에 모두 복사하는 replication방식과 일부 노드에만 복사하는dist 방식을 제공한다. 또, 통신모드는 동기(SYNC) 방식과 비동기(ASYNC) 두 가지 방식을 제공하고 있다. 기본값은 replication방식, 비동기 모드를 사용한다.
시스템 요건에 따라 다르겠지만, 대부분의 경우 위의 기본 설정으로도 충분한 성능과 신뢰성을 기대할 수 있다. 그러나 캐시 데이터 복제 모드에 대해서는 클러스터에 참여하는 노드 개수가 많을 경우 복제되는 객체의 개수 및 횟수가 많아져 메모리 이슈가 발생할 가능성이 있기 때문에 dist 모드로 변경하는 것이 좋다.
캐시 복제 모드
캐시 모드는 복제 대상을 클러스터 전체로 할 것인지, 임의의 노드로 할지를 설정하는 것이다. 전체를 대상으로 하려면 replication 모드를 선택하고, 임의의 노드로 복제하려면 distribution 모드를 선택한다. JBoss EAP 6는 기본값으로 replication 모드로 설정되어 있다.
replication 모드
클러스터 그룹내의 모든 서버 노드에 캐시를 복제한다. 모든 노드에 복제하기 때문에, 어느 서버 노드에 접속하더라도, 서버의 로컬에서 캐시 데이터를 사용할 수 있다.
그러나 모든 서버 노드에 캐시 데이터를 복제하기 때문에 네트워크 트래픽이 많고, 모든 노드의 복제본을 가지기 때문에 메모리 사용량도 많다. 또 SYNC 통신을 사용할 경우, 모든 서버 노드에 대해서 캐시 데이터 복제가 완료되어야 다음 작업을 처리할 수 있기 때문에, 서버 노드 수가 많아지면 캐시의 기록 속도가 느려져, 성능에 영향을 미치게 된다.
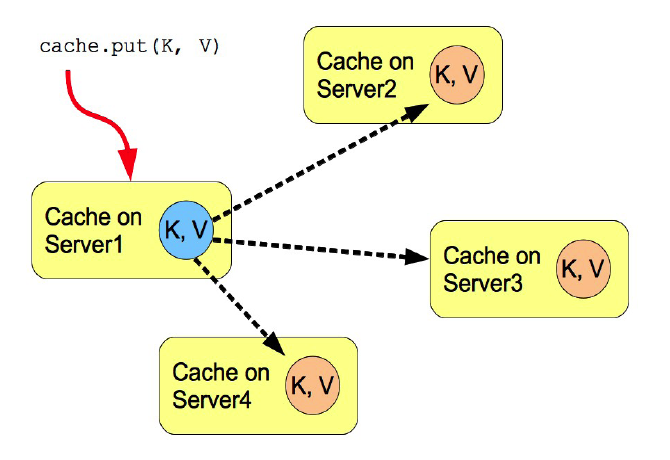
그림 . replication 모드의 복제 방법
distribution 모드
replication 모드는 전체서버 노드를 복제 대상으로 하고 있지만, distribution 모드는 캐시의 복제 대상을 클러스터내의 일부 노드들을 대상으로 한다. 또 복제 대상 서버 노드 개수를 임의로 설정할 수 있다. ��이를 캐시 오너 수(Cache Owner)라고 한다.
JBoss EAP 5 까지는 Buddy Replication이라고 하는 캐시 replication 모드가 있었다. 이것은 특정 서버가 클러스터 내의 선택한 특정 서버 노드(buddy)에만 복제하는 기능이다. Infinispan의 Distribution 모드는 Buddy Replication과 비슷해 보이지만, Distribution 모드는 복제 대상을 지정하지 않아도 내부 알고리즘으로 판단하여 각각의 캐시마다 분산하여 복제하는 점이 다르다.
Distribution 모드에서 캐시는 Consistent Hash알고리즘을 사용하여 관리한다. 캐시 복제 대상 개수를 지정하여 사용하기 때문에, 동기(SYNC) 통신을 사용하더라도, 캐시의 저장 속도에 영향을 덜 받게 된다.
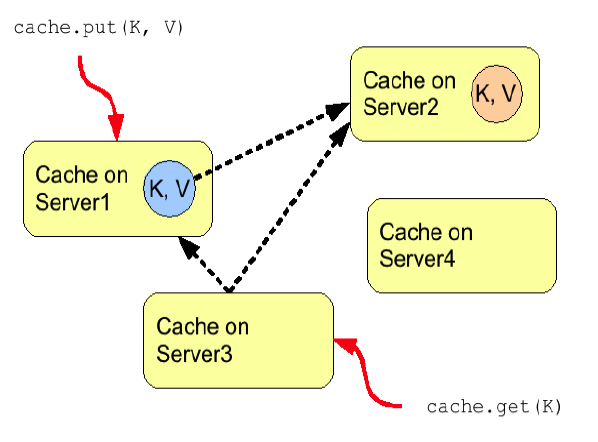
그림 16. dist 모드의 복제 방법
Consistent Hash
분산 캐시에 사용하는 해시 알고리즘이다. 단순한 해시에 키를 추가, 삭제했을 경우, 테이블의 사이즈 변경이 필요하여서, 키를 재 맵핑하는 시간이 오래 걸리게 된다. Consistent Hash을 이용하면 이 시간을 최소한으로 줄일 수 있다. Infinispan에서도 dist모드에서 어떤 노드에 데이터를 복제할지 결정하는데 이 알고리즘을 사용한다. 동적으로 노드의 개수가 증가하고 줄어드는 환경에서 자동으로 데이터를 분산하기 위해 사용하는 알고리즘이 Consistent Hash이다.
데이터를 저장하기 위한 대상 노드를 결정할 때 Consistent Hash 알고리즘을 이용하여 동적으로 노드 수가 증가하거나 감소할 때 자동��으로 데이터를 분산한다. Memcached, Amazon’s Dynamo, Cassandra그리고 Riak 등의 제품에서 Consistent Hashing 을 활용하여 파티셔닝을 구현했다.
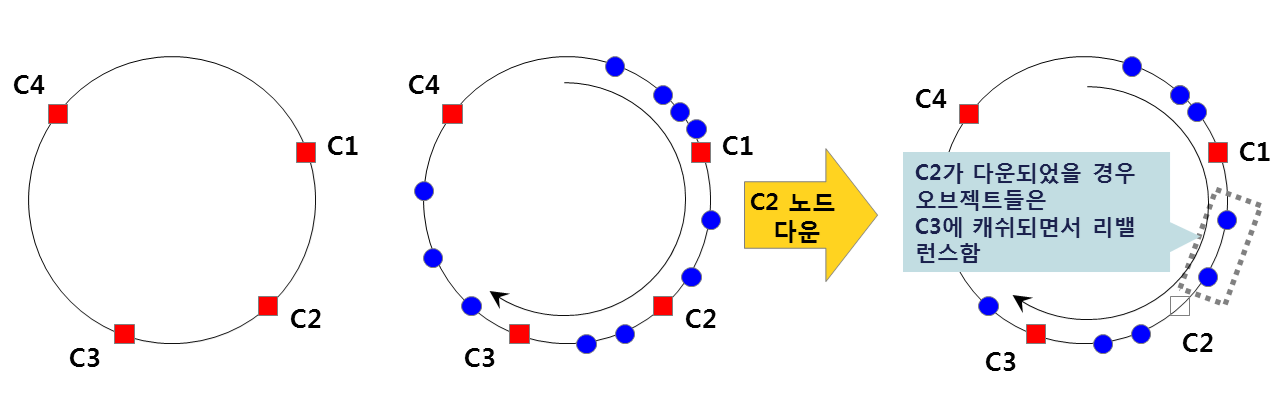
그림 . Consistent Hash
캐시 모드 변경 방법
캐시 모드를 Distribution 모드로 변경하려면 CLI 명령으로 아래와 같은 명령을 실행한다.
distribution 모드를 사용하는 경우 캐시 오너수도 설정할 수 있다.
따라하기
- web 캐시 컨테이너로 이동
- 캐시 모드를 distribution 모드로 변경
- 캐시 오너 수 변경
- web 캐시 컨테이너로 이동
[standalone@localhost:9999 /] **cd /subsystem=infinispan/cache-container=web**
-
캐시 모드를 distribution 모드로 변경
[standalone@localhost:9999 cache-container=web] :write-attribute(name=default-cache, value=dist)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
} -
캐시 오너수 변경
[standalone@localhost:9999 cache-container=web] cd distributed-cache=dist
[standalone@localhost:9999 distributed-cache=dist] :write-attribute(name=owners, value=3)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
EJB 애플리케이션의 경우에도 캐시모드를 변경하려면 위의 CLI에서 ‘cache-container=ejb’로 변경하여 설정하면 된다.
통신 방식
통신 방식은 비동기(ASYNC) 모드와 동기(SYNC) 모드의 두 가지 종류가 있다. 각각의 특징은 다음과 같다.
-
비동기(ASYNC) 모드
- 세션 복제시 비동기로 처리하여 응답 수신을 기다리지 않고 반환한다.
- 속도가 빠르다.
-
동기(SYNC) 모드
- 세션 복제시 모든 응답 수신이 완료되고 나서 응답을 준다.
- 백업까지 모두 성공적으로 된 것을 확인하기 때문에 신뢰성이 높다.
- 데이터 반영시 락을 걸고, 분산 2단계 커밋을 해서, 동일 데이터를 동시에 변경하면 에러가 발생한다.
- 속도가 상대적으로 느리다.
동기(SYNC) 모드로 변경하려면, CLI 명령으로 아래와 같이 설정을 변경한다.
[standalone@localhost:9999 /] cd /subsystem=infinispan/cache-container=web/replicated-cache=repl
[standalone@localhost:9999 replicated-cache=repl] :write-attribute(name=mode, value=SYNC)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}