애플리케이션별 상세정보
맵
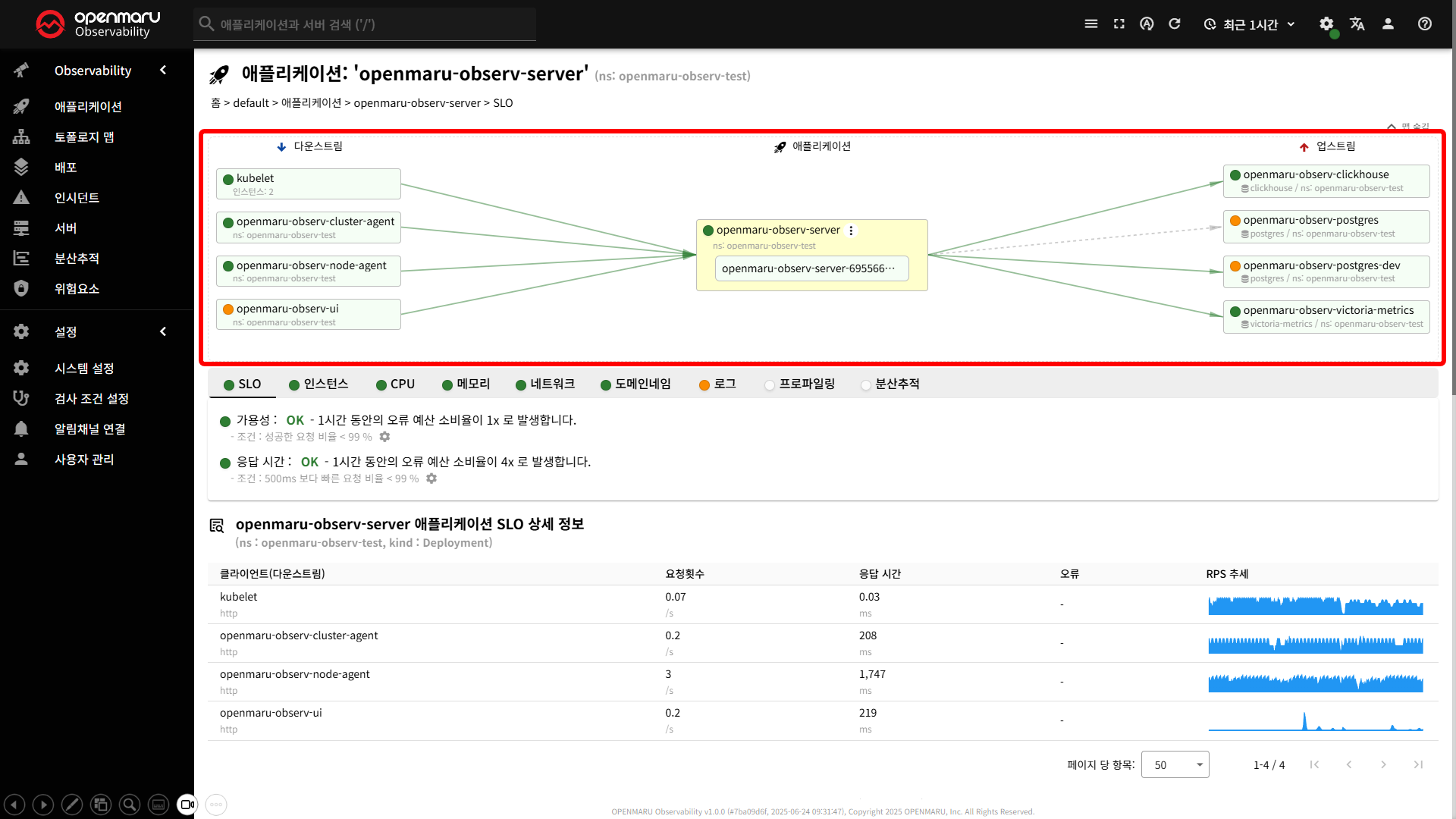
애플리케이션 맵은 애플리케이션과 그 주변 구성요소 간의 데이터 흐름과 의존 관계�를 시각적으로 보여줍니다.
이 맵은 다운스트림(Downstream) -> 애플리케이션(Application) -> 업스트림(Upstream) 구조로 구성되어 있습니다.
각 구성요소의 의미
- 다운스트림 : 애플리케이션(서버)에 데이터를 전송하거나 요청을 보내는 클라이언트, 에이전트, 프론트엔드 등
- 애플리케이션 : 다운스트림에서 받은 데이터를 처리하고, 업스트림에 저장하거나 조회하는 서버
- 업스트림 : 애플리케이션이 데이터를 저장하거나 조회하는 데이터베이스, MSA 서비스 등
SLO
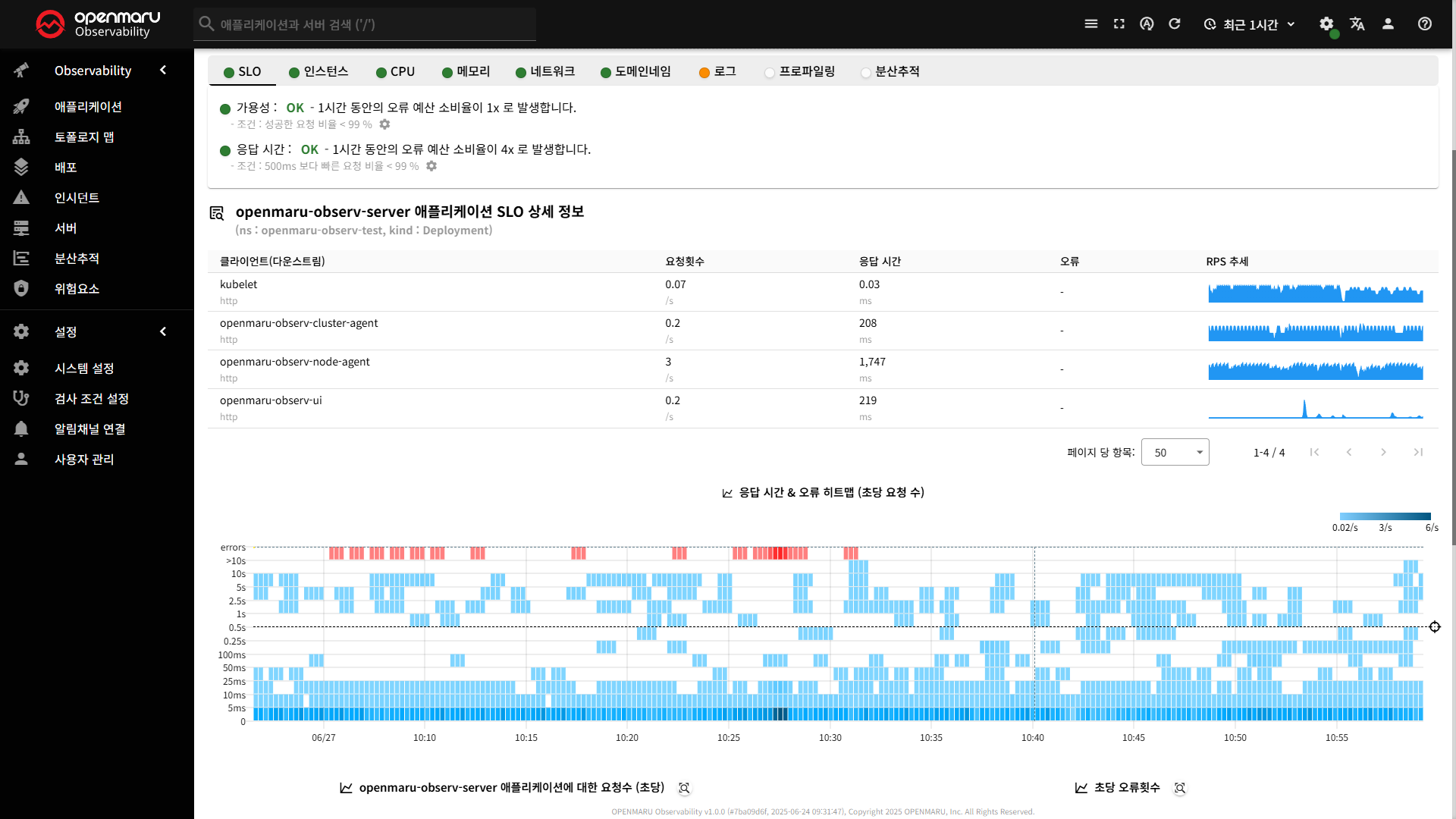
SLO(Service Level Objective) 탭은 애플리케이션의 서비스 수준 목표를 모니터링하고 관리하는 기능을 제공합니다. 이 탭에서는 애플리케이션의 가용성(Availability)과 응답 시간(Latency)에 대한 SLO를 설정하고, 실시간으로 SLO 준수율을 확인할 수 있습니다.
가용성 설정
- 서비스를 정상적으로 사용중인지 성공한 요청을 기준으로 모니터링
- 지표 설정
- 기본 값
- 사용자 정의 : 커스텀 prometheus 쿼리 사용
- 목표 설정
- 체크박스로 SLO 추적 활성화/비활성화
- 기본 값: 99%
- 설정 범위: 0-100%
- 조건: 성공한 요청 비율 > 임계값
응답시간 설정
- 오래 걸리는 요청을 모니터링
- 지표 설정
- 기본 값
- 사용자 정의 : 커스텀 히스토그램 쿼리 사용
- 목표 설정
- 체크박스로 SLO 추적 활성화/비활성화
- 기본 값: 95%
- 설정 범위: 0-100%
- 목표 시간 선택: 5ms, 10ms, 25ms, 50ms, 100ms, 250ms, 500ms, 1s, 2.5s, 5s, 10s
- 조건: 목표 시간안에 응답된 요청 비율 > 임계값
🟢 정상 (OK): 메모리 사용량이 정상 범위
🟠 경고 (Warning): 메모리 사용량이 높음
🔴 심각 (Critical): 메모리 사용량이 매우 높음
⚪ 알 수 없음 (Unknown): 데이터 부족
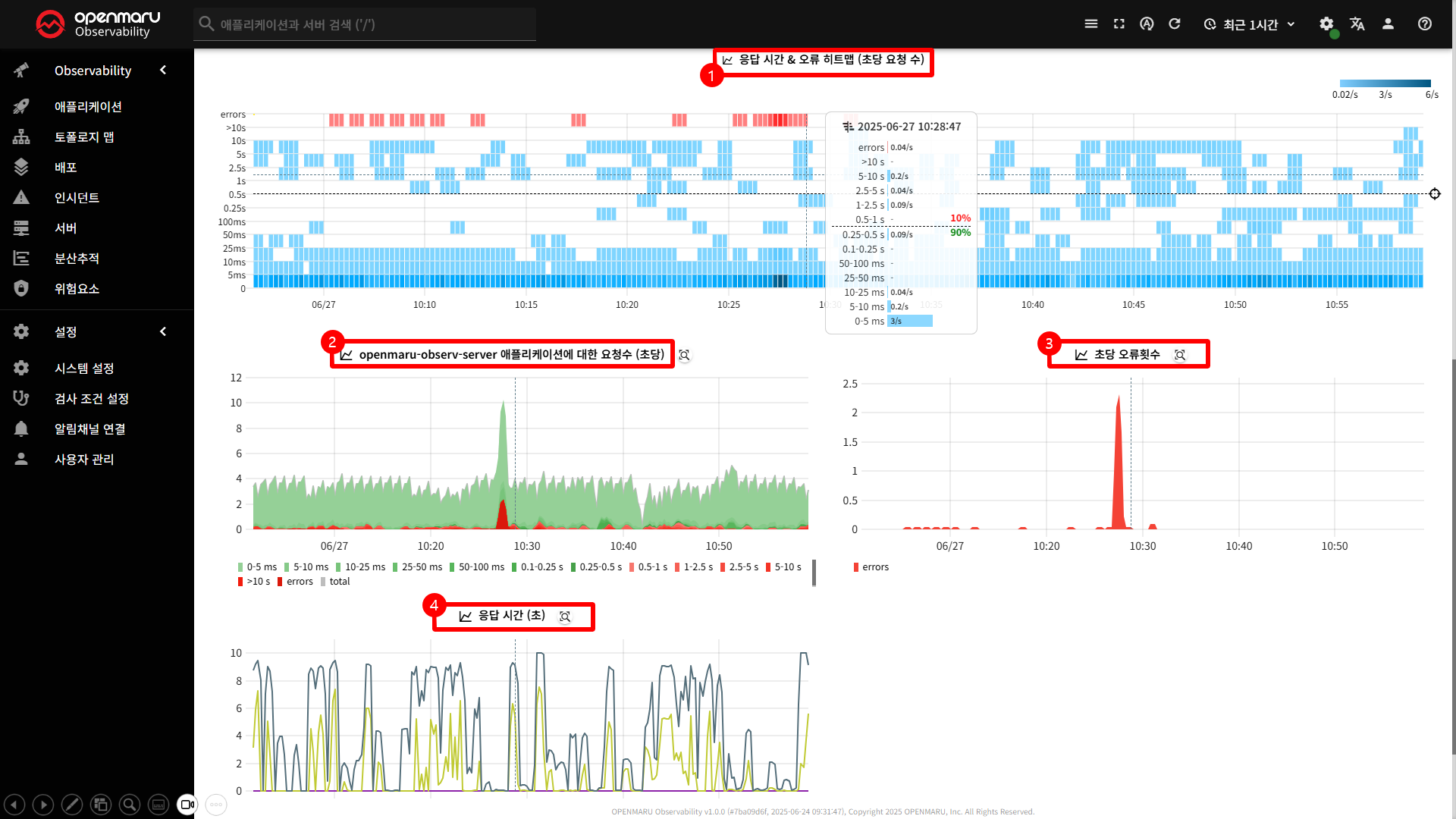
〽️ ① 응답 시간 & 오류 히트맵
응답 시간 분포와 오류 발생 패턴을 시각적으로 분석
- 요청 수에 따른 색상 변화 ( 연한색 -> 진한색 )
- 마우스 Hover : 해당 시점의 응답 시간별 요청 수 확인
- 임계값 표시 : SLO 목표 시간을 기준으로 점선 표시
〽️ ② 애플리케이션에 대한 요청 수
애플리케이션�의 트래픽 패턴과 부하를 분석
〽️ ③ 초당 오류횟수
애플리케이션의 오류 발생 패턴과 빈도 분석
〽️ ④ 응답 시간
응답 시간과 성능을 분석
- P50, P95, P99 등 다양한 백분위수 표시
- 전체 데이터 중 특정 비율의 데이터의 평균 값을 나타냄
- 예를들어, p50 그래프는 응답시간이 빠른 상위 50%의 평균 응답시간을 나타냄
🔹 마우스 오버: 특정 시간대의 상세 정보를 툴팁으로 표시
🔹 차트 선택: 마우스 드래그로 특정 영역 선택 가능
🔹 차트 동기화: 다른 차트와 커서 위치 동기화
인스턴스
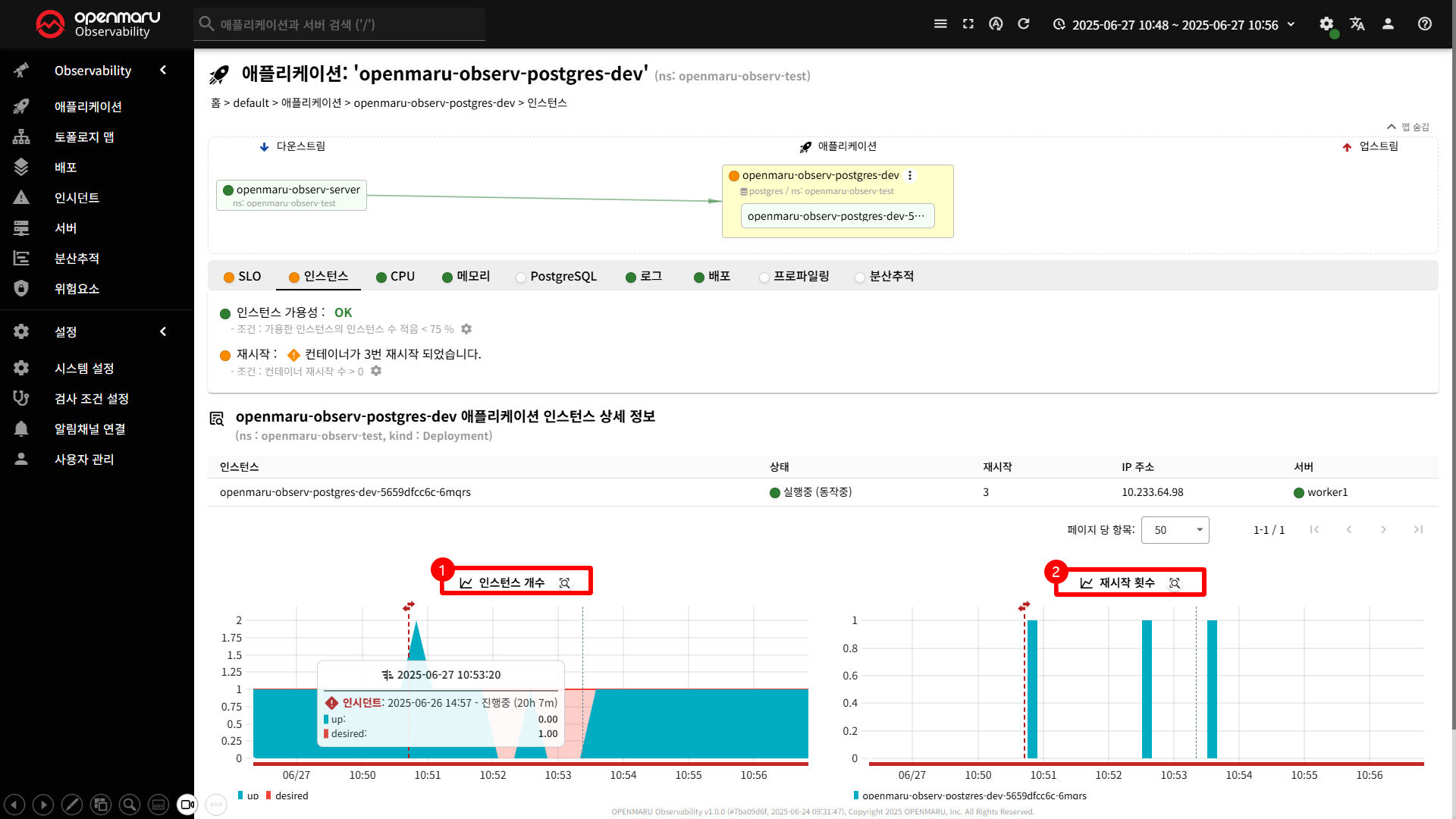
인스턴스 탭은 애플리케이션의 개별 인스턴스들을 모니터링하고 관리하는 기능을 제공합니다.
이 탭에서는 애플리케이션의 각 인스턴스별 상태, 가용성, 재시작 횟수 등을 확인할 수 있습니다.
인스턴스 가용성 설정
- 애플리케이션 인스턴스의 가용성을 모니터링
- 기본값: 80%
- 설정 범위: 0-100%
- 조건: 가용한 인스턴스 수 < 임계값
재시작 수 설정
- 컨테이너가 재시작 된 수를 모니터링
- 기본값: 5회
- 설정 범위: 0 이상
- 조건: 컨테이너 재시작 수 > 임계값
- 전역 기본값 : 시스템 전체에 적용되는 기본설정으로 모든 프로젝트와 애플리케이션에 공통 적용
- 프로젝트 수준 : 해당 프로젝트의 모든 애플리케이션에 적용
- 애플리케이션 수준 : 해당 애플리케이션에만 적용
〽️ ① 인스턴스 개수
인스턴스 수 변화 추적
- 목표 인스턴스 중 가용되는 인스턴스 수 확인
〽️ ② 재시작 횟수 인스턴스 재시작 패턴 분석
- 시간 별 재시작 횟수, 재시작 빈도 및 추세 확인
CPU
CPU 탭은 애플리케이션의 CPU 사용량과 관련된 성능 지표를 모니터링하고 분석하는 기능을 제공합니다.
이 탭에서는 노드와 컨테이너 수준의 CPU 사용률, CPU 점유 프로세스, CPU 대기 시간, CPU 스로틀링 등의 상세�한 정보를 확인할 수 있습니다.
노드 CPU 사용량 설정
- 노드 전체의 CPU 부하 모니터링
- 기본값: 80%
- 설정 범위: 0-100%
- 조건: 서버 CPU 사용량 < 임계값
컨테이너 CPU 사용량 설정
- 개별 컨테이너의 CPU 사용량 모니터링
- 기본값: 80%
- 설정 범위: 0-100%
- 조건: 컨테이너 CPU 사용량 > 임계값
〽️ ① CPU 사용량 차트
시간에 따른 CPU 사용률 변화 추적
- 단위 : 밀리코어 (millicores)
- 1 코어 = 1000 밀리코어
- 1 밀리코어 = 0.001 코어
〽️ ② 평균 로드 차트
시스템의 부하를 분석
- 각 노드 별로 개별 차트 생성
- limit 값 : 각 노드의 CPU 코어 수의 2배
〽️ ③ CPU 대기 시간 차트
CPU가 I/O나 다른 리소스를 기다리는 시간 분석
- 원인: CPU 제한, 노드의 높은 CPU 사용률, 다른 프로세스와의 경합 등
〽️ ④ CPU 속도제한(스로틀링) 시간 차트
컨테이너의 CPU 제한으로 인한 성능 저하 분석
- 원인: 컨테이너의 CPU 제한에 도달하여 시스템에 의해 CPU 사용이 제한됨
- CPU 대기시간은 모든 종류의 CPU 대기 시간 (스로틀링 포함)
- Throttled Time 은 CPU 제한으로 인한 스로틀링만 해당
따라서 CPU Delay가 Throttled Time보다 클 수 있으며, 이는 노드의 높은 CPU 사용률이나 다른 프로세스와의 경합으로 인한 대기 시간을 나타냅니다.
〽️ ⑤ 서버 CPU 사용량 차트
각 CPU 사용 모드별 CPU 사용률을 백분율로 표시
- 시스템 레벨 CPU 사용 분석
- 가상화 환경 모니터링: Steal 시간을 통해 호스트 시스템의 부하 확인
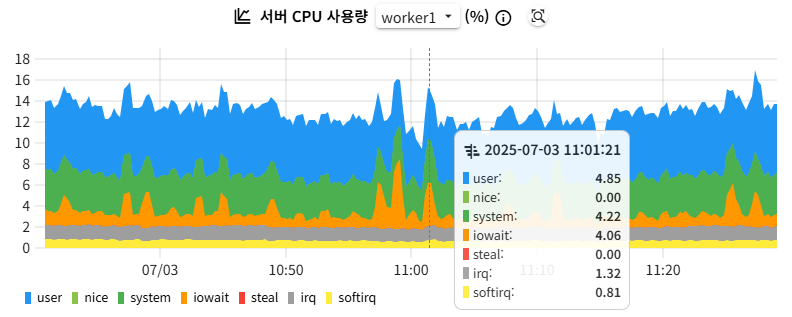
- 모드별 분류
- User (파란색): 일반 사용자 프로세스
- Nice (연한 녹색): nice 값이 조정된 낮은 우선순위 프로세스
- System (녹색): 커널 모드에서 실행되는 시스템 프로세스
- I/O Wait (주황색): I/O 작업 완료를 기다리는 유휴 상태
- IRQ (회색): 하드웨어 인터럽트 서비스
- SoftIRQ (노란색): 소프트웨어 인터럽트 서비스
- Steal (빨간색): 가상 머신에서 호스트 시스템에 의해 빼앗긴 부분
〽️ ⑥ CPU 점유프로세스 차트 어떤 애플리케이션이 CPU 를 많이 사용하는지 식별
- 애플리케이션 레벨 리소스 사용량 분석
메모리
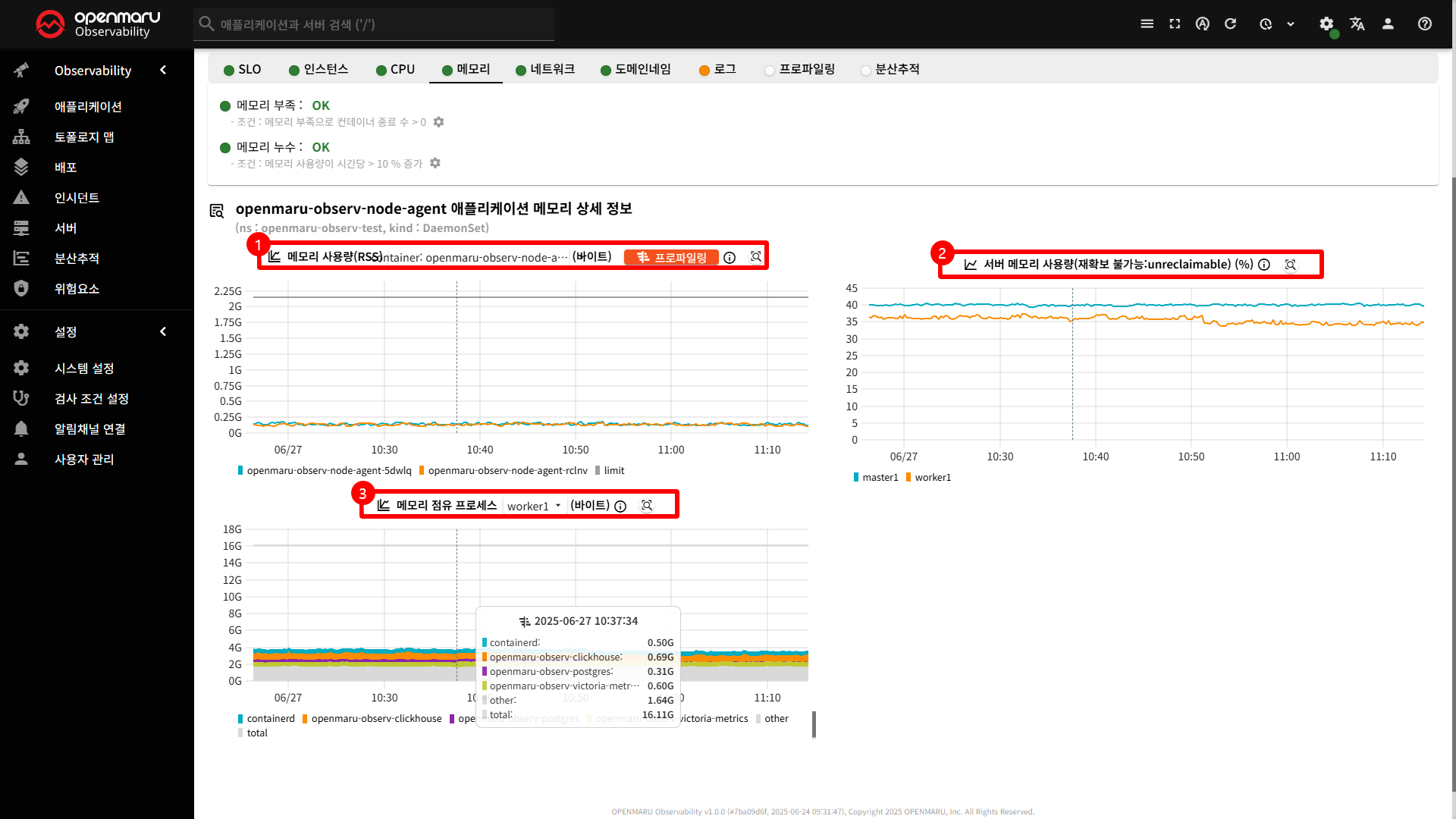
메모리 탭은 애플리케이션의 메모리 사용량과 관련된 모든 정보를 종합적으로 모니터링하고 분석할 수 있는 기능을 제공합니다.
이 탭을 통해 메모리 누수, 메모리 부족(OOM) 상황, 메모리 사용량 추세 등을 실시간으로 감지하고 대응할 수 있습니다.
메모리 부족 설정
- 컨테이너가 메모리 부족으로 인해 OOM Killer에 의해 종료되는 상황을 모니터링
- 기본값: 1회
- 설정 범위: 0 이상
- 조건: 서버 CPU 사용량 < 임계값
메모리 누수 설정
- 시간 당 메모리 증가율(%)을 모니터링
- 기본값: 5%
- 설정 범위: 0-100%
- 조건: 컨테이너 CPU 사용량 > 임계값
〽️ ① 메모리 사용량(RSS) 차트
애플리케이션의 실제 메모리 사용량 RSS 기반으로 측정하여 바이트 단위로 표시
- RSS (Resident Set Size) : 프로세스가 실제로 물리적 메모리에 로드된 페이지의 크기이며, 파일 I/O 캐시 메모리는 제외.
- 컨테이너 별 차트 생성
- 메모리 누수 감지
- RSS : 물리적 메모리로 실제 메모리 사용량 분석가능
- Cache : 페이지 캐시 메모리로 파일 I/O 성능 분석가능
전체 메모리 사용량 = RSS + Cache
〽️ ② 서버 메모리 사용량 차트
노드 레벨에서 메모리 사용량 확인 ( 재확보 불가능한 메모리 포함 )
Linux 커널이 즉시 해제할 수 없는 메모리를 의미하며, 이는 시스템의 메모리 부족 상황에서도 커널이 강제로 회수할 수 없는 메모리영역.
커널 메모리, 디스크 캐시, 네트워크 버퍼 등
〽️ ③ 메모리 점유프로세스 차트
각 노드마다 별도의 차트 생성
- 애플리케이션 레벨 메모리 사용량 분석
네트워크
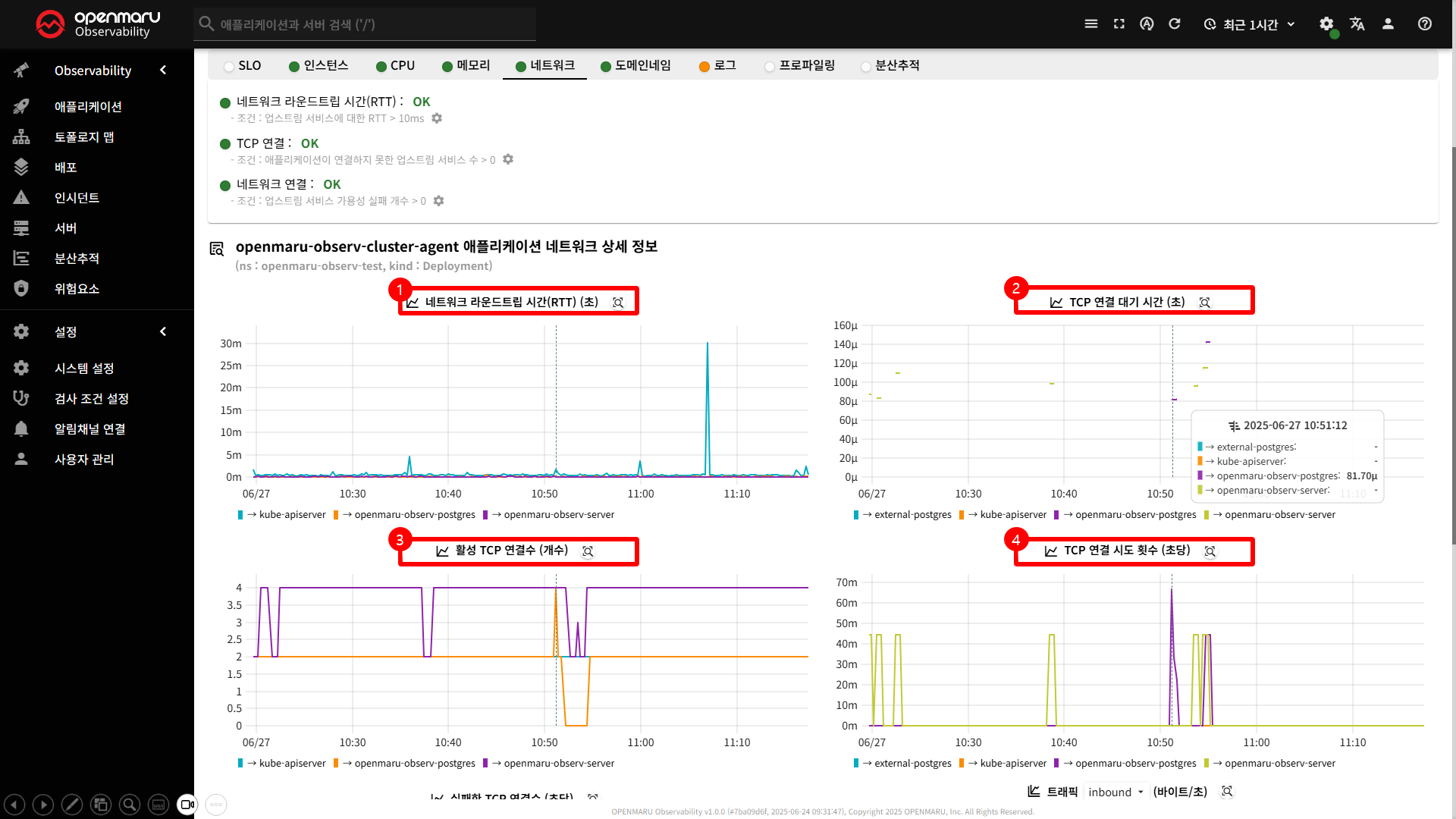
네트워크 탭은 애플리케이션의 네트워크 성능과 연결 상태를 종합적으로 모니터링하고 분석할 수 있는 기능을 제공합니다.
이 탭을 통해 네트워크 지연 시간, 연결 실패, 패킷 손실, 대역폭 사용량 등을 실시간으로 감지하고 대응할 수 있습니다.
네트워크 라운드 트립 시간 (RTT) 설정
- 애플리케이션과 업스트립 서비스 간의 네트워크 지연 시간을 'ms' 단위로 모니터링
- 기본값: 100ms
- 설정 범위: 0 이상
- 조건: 업스트림 서비스에 대한 RTT > 임계값
TCP 연결 설정
- 현재 연결되지 못한 TCP 연결의 개수를 모니터링
- 기본값: 0개
- 설정 범위: 0 이상
- 조건: CPU 연결 실패 개수 > 임계값
네트워크 연결 설정
- 업스트림 서비스 중 연결되지 못한 개수를 모니터링
- 기본값: 0개
- 설정 범위: 0 이상
- 조건: 업스트림 서비스 가용성 실패 개수 > 임계값
〽️ ① 네트워크 라운드트립 시간 차트
네트워크 라운드트립 시간(Round-Trip Time, RTT) 차트는 애플리케이션과 업스트림 서비스 간의 네트워크 지연 시간(ms)을 측정하여 표시합니다.
- 측정 방법 : 애플리케이션에서 업스트림 서비스로 패킷(ICMP)을 보내고 응답을 받는 데 걸리는 총 시간
- 대상 : 컨테이너가 현재 통신중인 대상 애플리케이션
〽️ ② TCP 연결 대기 시간 차트
TCP 연결 대기 시간 차트는 TCP 연결을 설정하는 데 걸리는 시간(�μ)을 측정하여 표시합니다.
- 측정 방법 : TCP 3-way handshake ( SYN, SYN-ACK, ACK) 완료까지의 시간
3-way handshake
① SYN: 클라이언트가 서버에 연결 요청
② SYN-ACK: 서버가 연결 수락 응답
③ ACK: 클라이언트가 연결 확인
〽️ ③ 활성 TCP 연결수 차트
활성 TCP 연결수 차트는 현재 애플리케이션에서 유지하고 있는 활성 TCP 연결의 개수를 실시간으로 표시합니다.
〽️ ④ TCP 연결 시도 횟수 차트
TCP 연결 시도 횟수 차트는 애플리케이션 별로 TCP 연결 횟수를 표시합니다.
- 연결시도가 높을 경우 트래픽 증가, 연결 풀 부족, 서비스 장애 가능성
- 연결시도가 낮은 경우 트래픽 감소 혹은 연결 재사용 효율이 높을 가능성
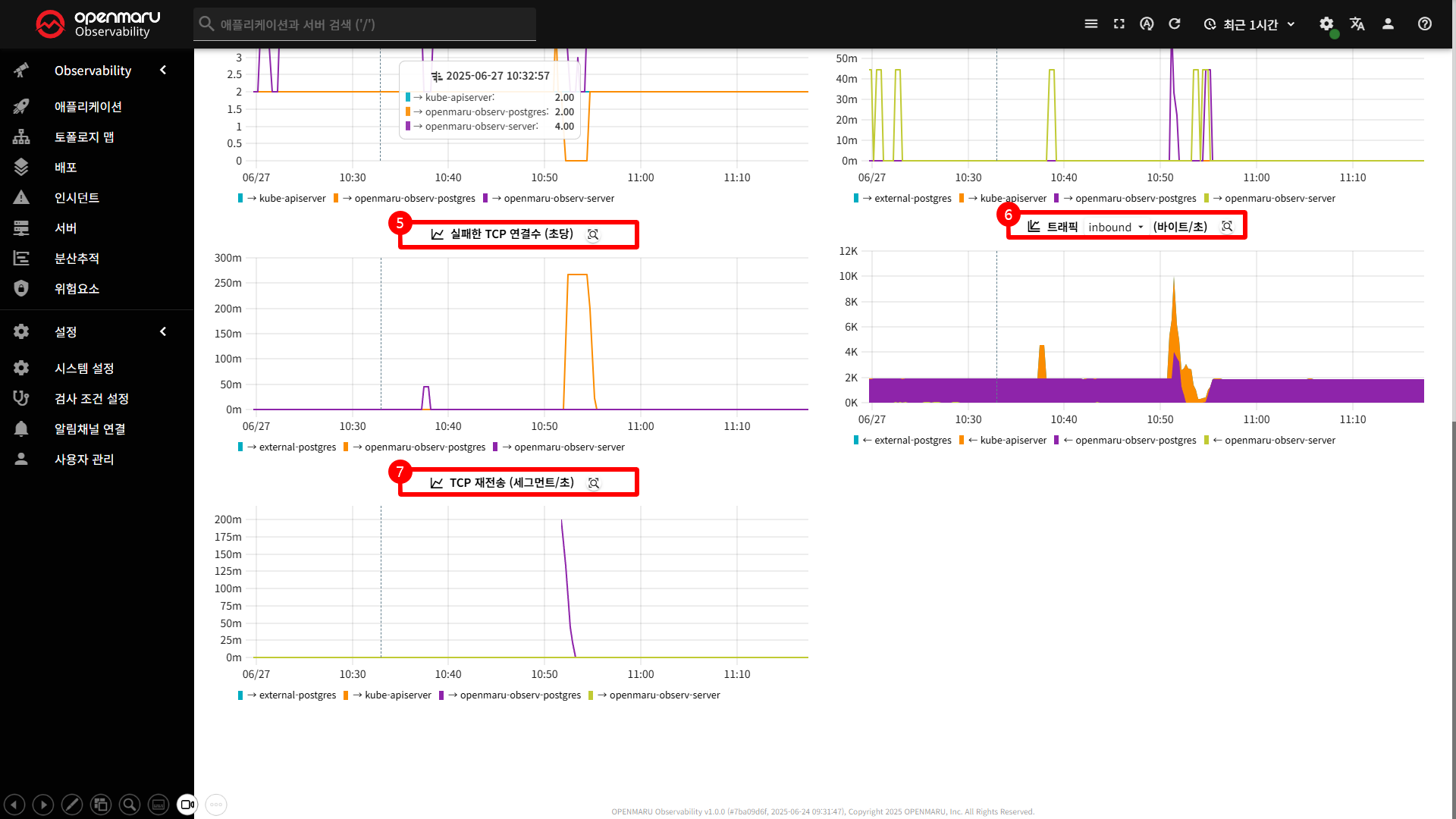
〽️ ⑤ 실패한 TCP 연결수 차트
실패한 TCP 연결수 차트는 초당 실패한 TCP 연결의 개수를 측정하여 표시합니다.
- TCP 연결 실패가 높을 경우 네트워크, 서비스 장애, 연결 풀 고갈 등 확인 필요
〽️ ⑥ 트래픽 차트
트래픽 차트는 네트워크 인터페이스의 수신(inbound)과 송신(outbound) 트래픽을 실시간�으로 표시합니다.
〽️ ⑦ TCP 재전송
TCP 재전송 차트는 TCP 세그먼트 재전송 횟수를 측정하여 네트워크 패킷 손실을 표시합니다.
- 재전송 횟수가 높을 경우 네트워크 품질저하, 패킷 손실, 대역폭 등 확인 필요
- 높은 RTT + 높은 재전송 :
- 높은 RTT + 높은 재전송: 네트워크 지연과 패킷 손실 동시 발생
- 높은 RTT + 낮은 재전송: 네트워크 지연은 있지만 안정적
- 연결 실패와의 관계
- 높은 재전송 + 연결 실패: 심각한 네트워크 문제
- 높은 재전송 + 연결 성공: 네트워크 품질 저하하지만 연결은 유지
도메인 네임
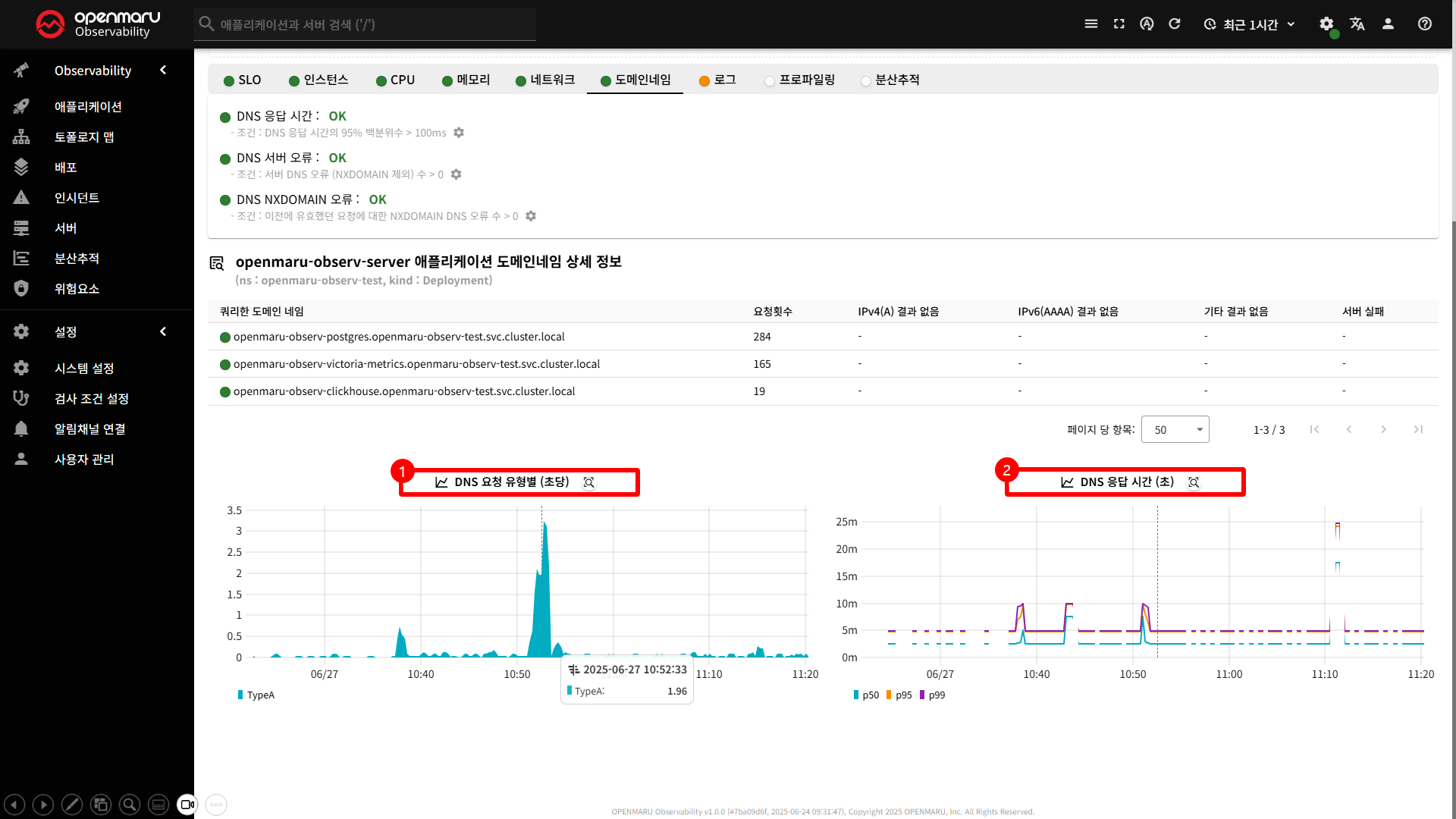
도메인 네임 탭은 애플리케이션의 DNS(Domain Name System) 성능과 관련된 모든 정보를 종합적으로 모니터링하고 분석할 수 있는 기능을 제공합니다.
이 탭을 통해 DNS 응답 시간, DNS 오류, DNS 요청 패턴 등을 실시간으로 감지하고 대응할 수 있습니다.
DNS 응답 시간 설정
- DNS 응답 시간의 95% 백분위수
- 기본값: 100ms
- 설정 범위: 0 이상
- 조건: DNS 응답 시간의 95% 백분위수 > 임계값
DNS 서버 오류 설정
- 서버 DNS 의 오류 수 (NXDOMAIN 제외)
- 기본값: 5개
- 설정 범위: 0 이상
- 조건: 서버 DNS 오류 (NXDOMAIN 제외) 수 > 임계값
DNS NXDOMAIN 오류
- **서버 NXDOMAIN 의 오류 수 **
- 기본값: 3개
- 설정 범위: 0 이상
- 조건: 이전에 유효했던 요청에 대한 NXDOMAIN DNS 오류 수 > 임계값
Non-Existent Domain 으로 "존재하지 않는 도메인"을 의미합니다. (응답코드: 3)
원인은 잘못된 도메인 입력, 도메인의 만료, DNS 서버 캐시 문제 등이 있습니다.
〽️ ① DNS 요청 유형별 차트
DNS 요청 유형 별 응답 시간을 집게합니다.
- A 레코드 : IPv4 주소 조회
- AAAA 레코드 : IPv6 주소 조회
- CNAME 레코드: 별칭 조회
- MX 레코드: 메일 서버 조회
- TXT 레코드: 텍스트 정보 조회
- 기타 레코드: 기타 DNS 레코드 유형
〽️ ② DNS 응답 시간 차트
DNS 응답 시간을 백분위수 별로 집게합니다.
전체 데이터 중 특정 비율의 데이터가 해당 값 이하에 있음을 나타내는 지표입니다.
- 표기법 : p50, p95, p99 (p=percent)
- 의미 : 예를들어 p95 = 100ms 라면, 전체 DNS 쿼리의 95% 가 100ms 이하로 응답됨을 의미
p50 은 전체 DNS 쿼리의 50% 가 이 시간 이하로 응답된다는 뜻으로 '중앙 값'을 의미합니다.
JVM
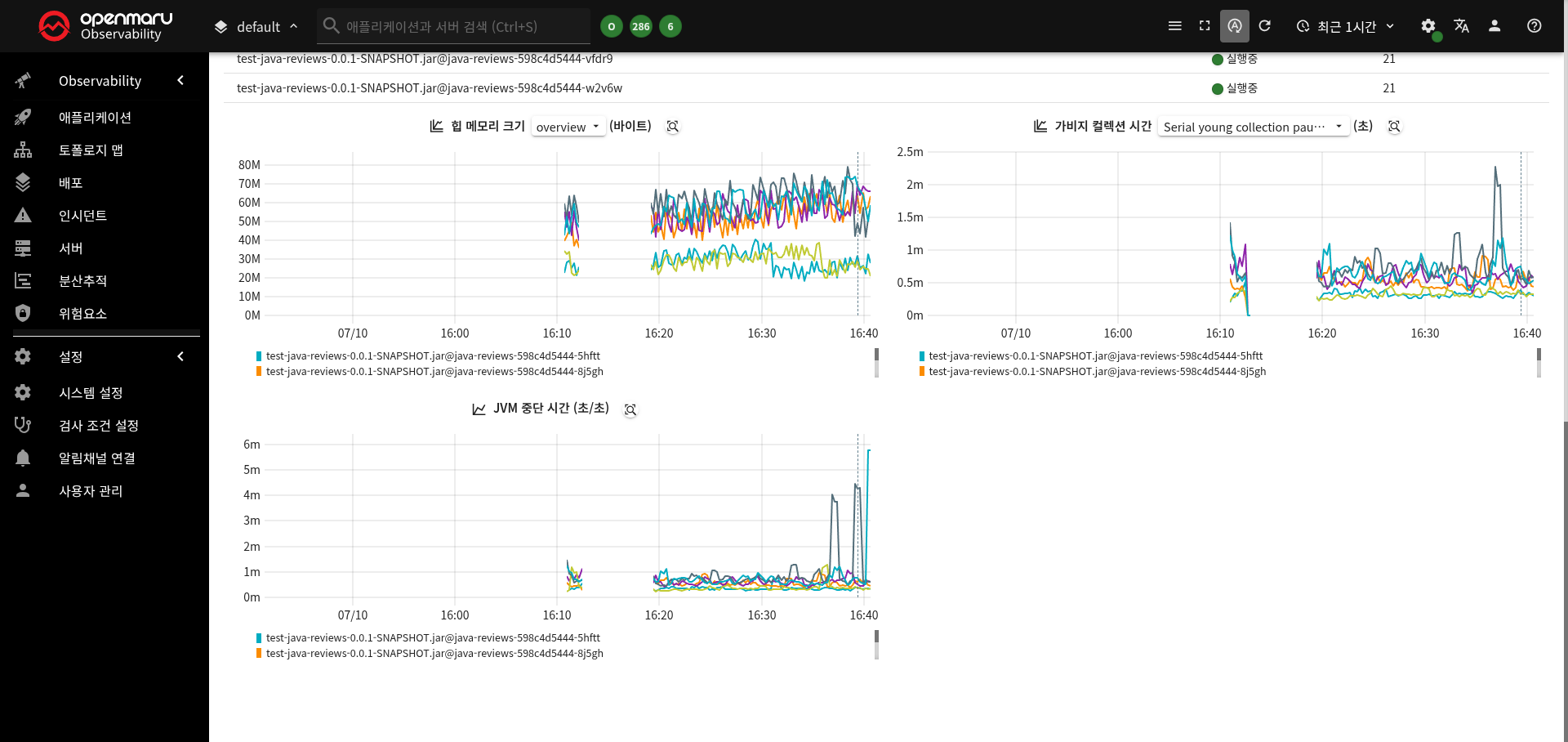
JVM 상태를 관측하고 문제를 조기 진단하기 위한 화면입니다. 아래 대시보드는 주요 JVM 지표(메모리 사용량, GC 시간, JVM 중단 시간 등)를 시각적으로 나타내며, 성능 이상 징후나 리소스 병목 여부를 쉽게 파악할 수 있습니다.
JVM 가용성 설정
- 비정상 컨테이너를 모니터링
- 기본값: 0
- 설정 범위: 0 이상
- 조건: JVM 인스턴스 가용성 실패 수 > 임계값
JVM 중지시간 설정
- 컨테이너의 GC등 safepoint 작업을 시간을 모니터링
- 기본값: 0.05
- 설정 범위: 0.05 이상
- 조건: 애플리케이션이 GC등 safepoint 작업을 위해 중지된 시간 > 50ms
로그
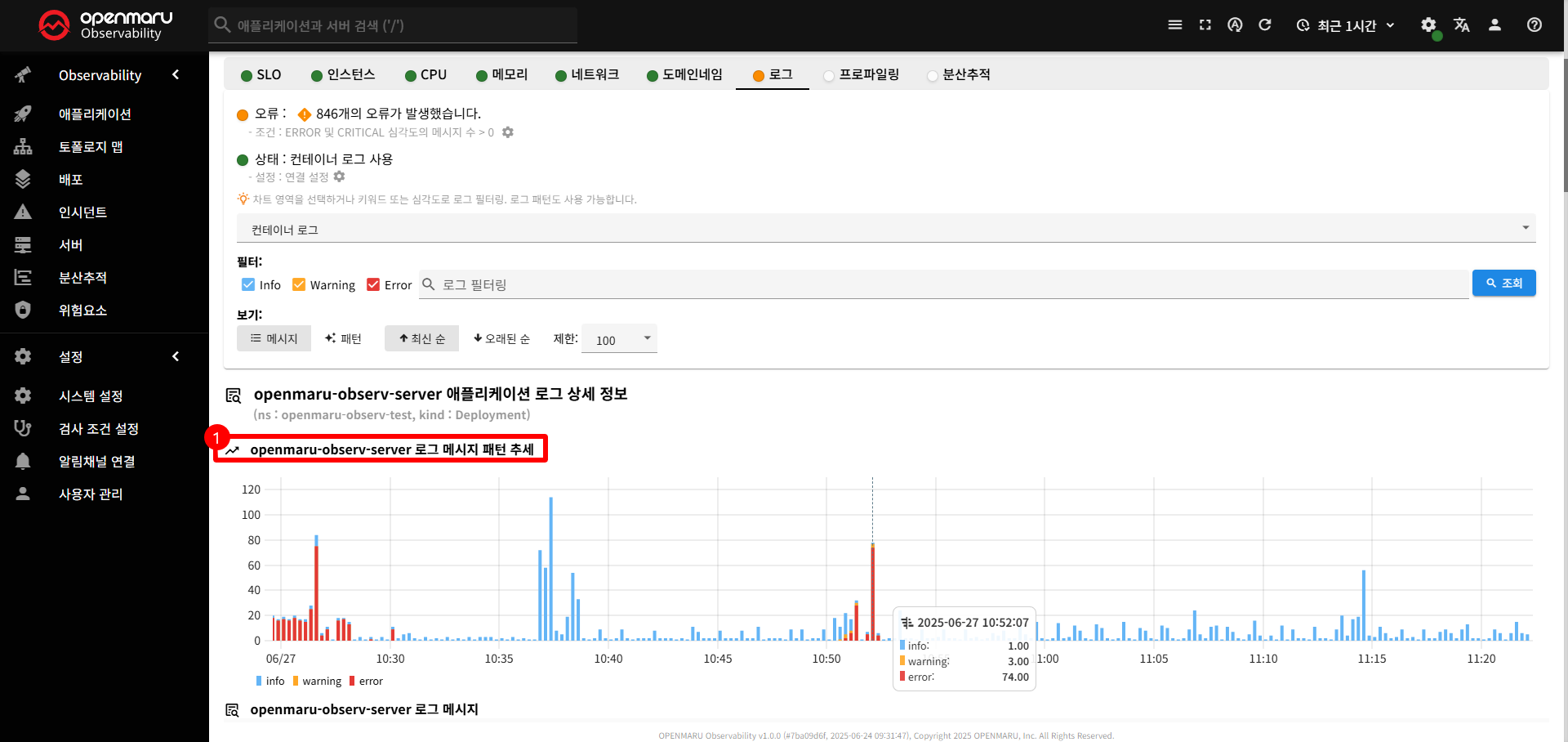
로그 탭은 애플리케이션의 로그 데이터를 종합적으로 모니터링하고 분석할 수 있는 기능을 제공합니다.
이 탭을 통해 로그 메시지, 로그 패턴, 로그 심각도별 분석 등을 실시간으로 수행하고 문제를 빠르게 진단할 수 있습니다.
오류 설정
- Error 와 Critical 레벨의 로그 갯수에 대한 임계값을 설정
- 기본값: 0개
- 설정 범위: 0 이상
- 조건: ERROR 및 CRITICAL 심각도의 메시지 수 > 임계값
상태 설정
- 로그 소스 선택
- 기본값: 컨테이너 로그 사용
- 설정 범위: OpenTelemetry Service 지정
로그 소스 선택
- OpenTelemetry : 애플리케이션에서 직접 전송하는 구조화된 로그로 다양한 플랫폼과 언어를 지원
- Container Logs : 컨테이너에서 수집되는 로그
필터링
- 로그 레벨 별 필터링 기능
- 로그 메시지 내용에서 키워드 검색 기능
메시지/패턴 보기
- 로그의 패턴을 보여주며, "이 패턴의 로그 메시지 보기" 버튼으로 해당 패턴의 로그를 모아볼 수 있는 기능 제공
- 정렬: 최신 순 / 오래된 순 정렬 기능
- 제한: 출력 될 로그 갯수를 제한 ( 10, 20, 50, 100, 1000 개 )
〽️ ① 로그 메시지 패턴 추세 차트
시간 별 로그 발생량을 로그 레벨별로 구분하여 표시합니다.
만약 패턴 보기로 변경하면, 로그 패턴별로 구분하여 표시합니다.
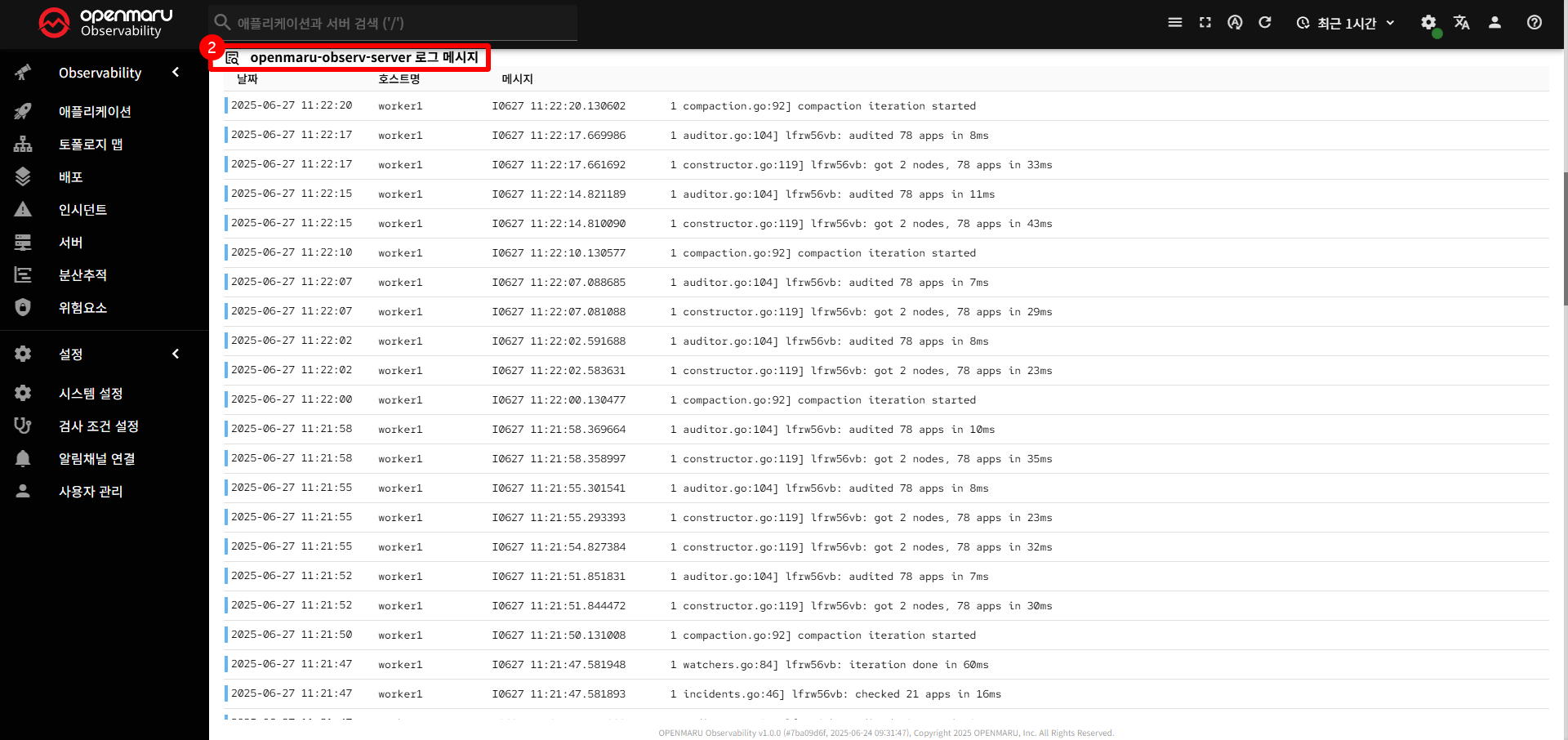
〽️ ② 로그 메시지 상세보기 테이블 테이블 구성
- 날짜 : 로그 발생 시간 (YYYY-MM-DD HH:mm:ss)
- 호스트명: 로그가 발생한 서버/인스턴스
- 메시지: 실제 로그 내용 (색상으로 심각도 구분)
- 🟦 info
- 🟥 error
- 메시지 상세 보기
-
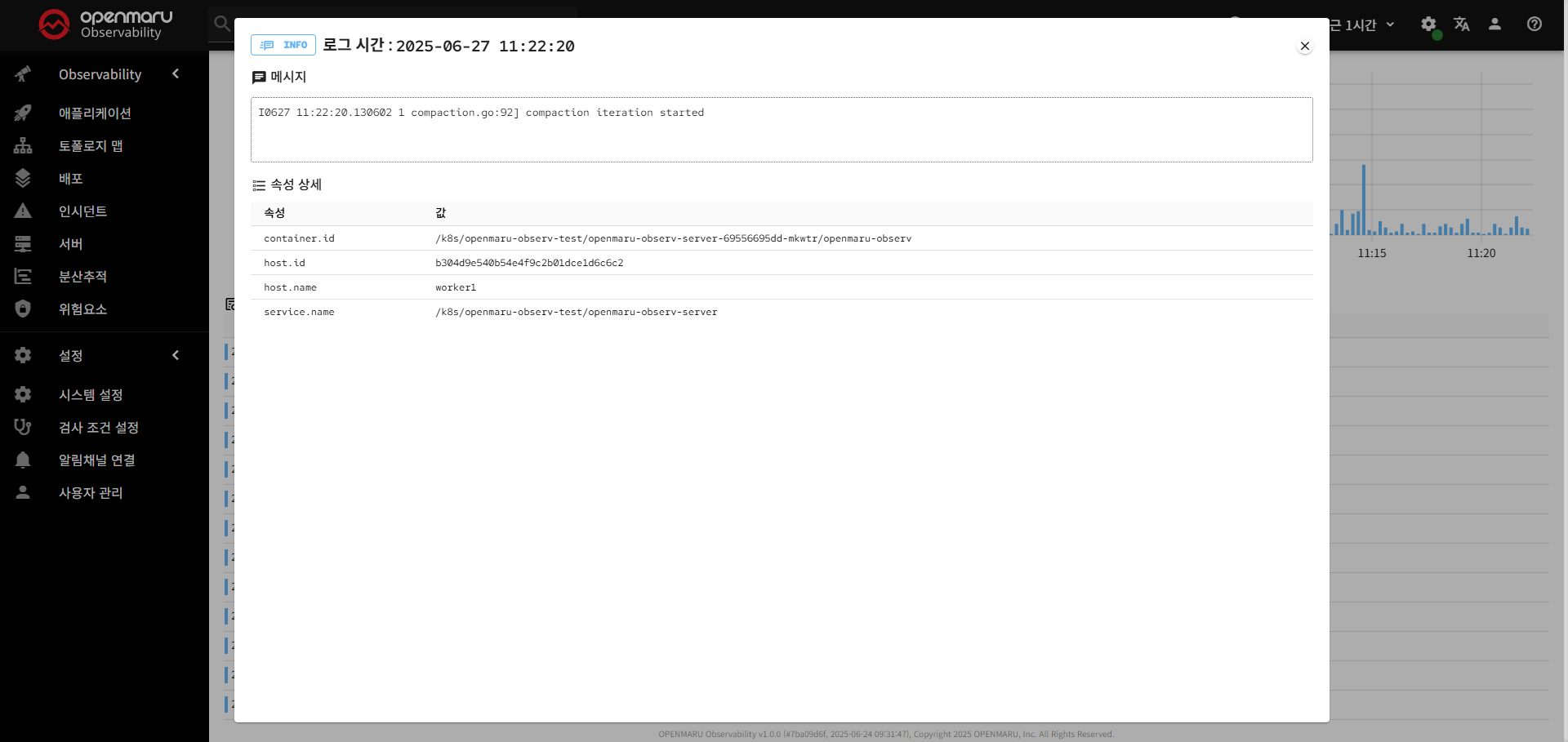
- 클릭 시: 로그 메시지의 상세 내용을 팝업으로 표시
- JSON 하이라이팅: JSON 형태의 로그는 구문 강조 표시
- 속성 정보: 로그의 추가 메타데이터 표시
-
배포
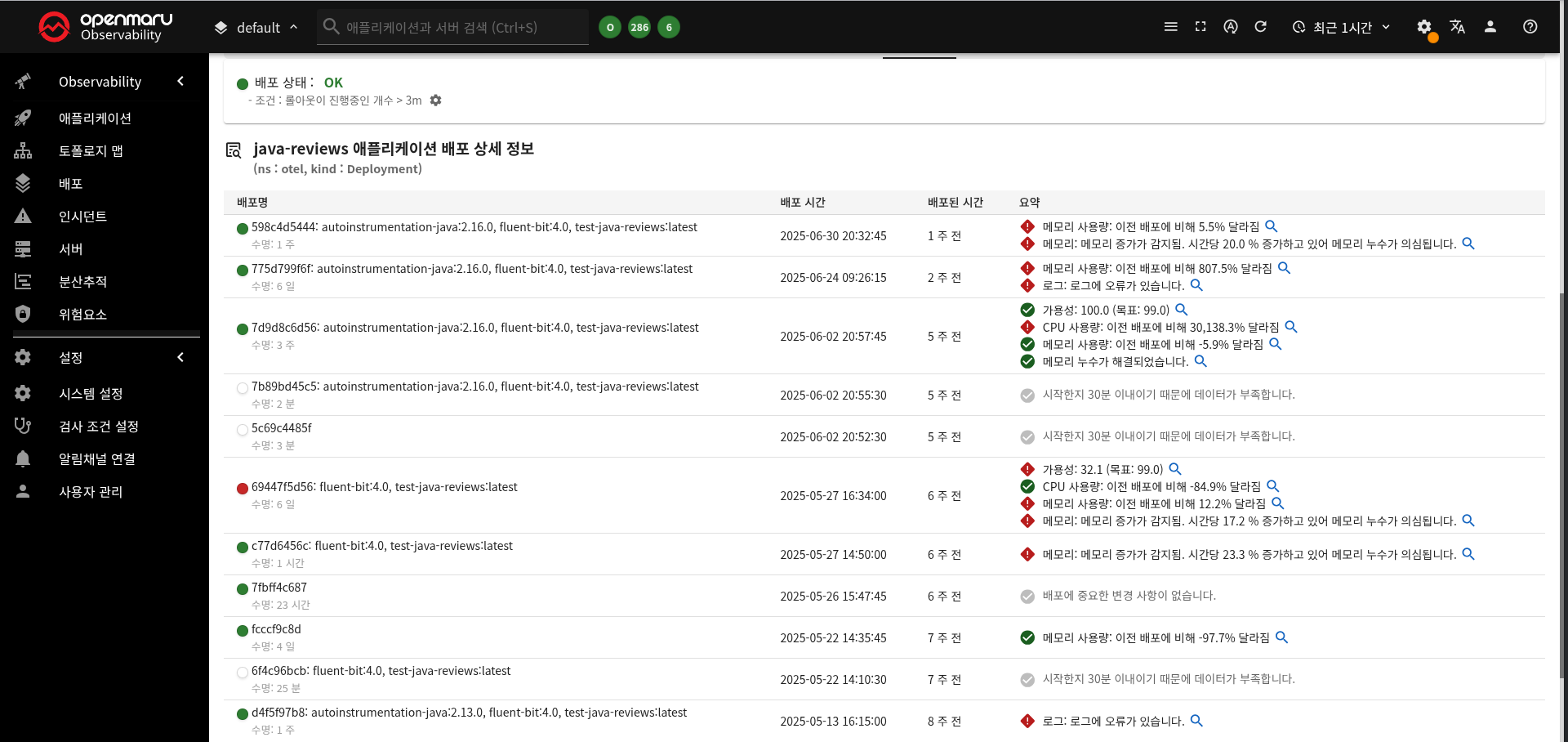
Deployment의 배포 내역을 확인할 수 있고, 이전 배포 버전과의 차이점을 확인할 수 있습니다.
배포 상태 설정
- 롤아웃 중인 시간을 모니터링
- 기본값: 180s
- 설정 범위: 0 이상
- 조건: 롤아웃이 진행중인 갯수 > 임계값
프로파일링
프로파일링 탭은 애플리케이션의 성능 프로파일을 분석하여 CPU 사용량, 메모리 할당, 함수 호출 스택 등을 시각적으로 표시하는 기능을 제공합니다.
이 탭을 통해 애플리케이션의 성능 병목 지점을 정확히 파악하고 최적화할 수 있습니다.
프로파일링
- 드롭다운 메뉴로 사용 가능한 프로파일 타입선택
- 설정 항목: CPU 프로파일, 메모리 프로파일, 고루틴 프로파일, 기타 프로파일 등
〽️ ① 플레임 그래프
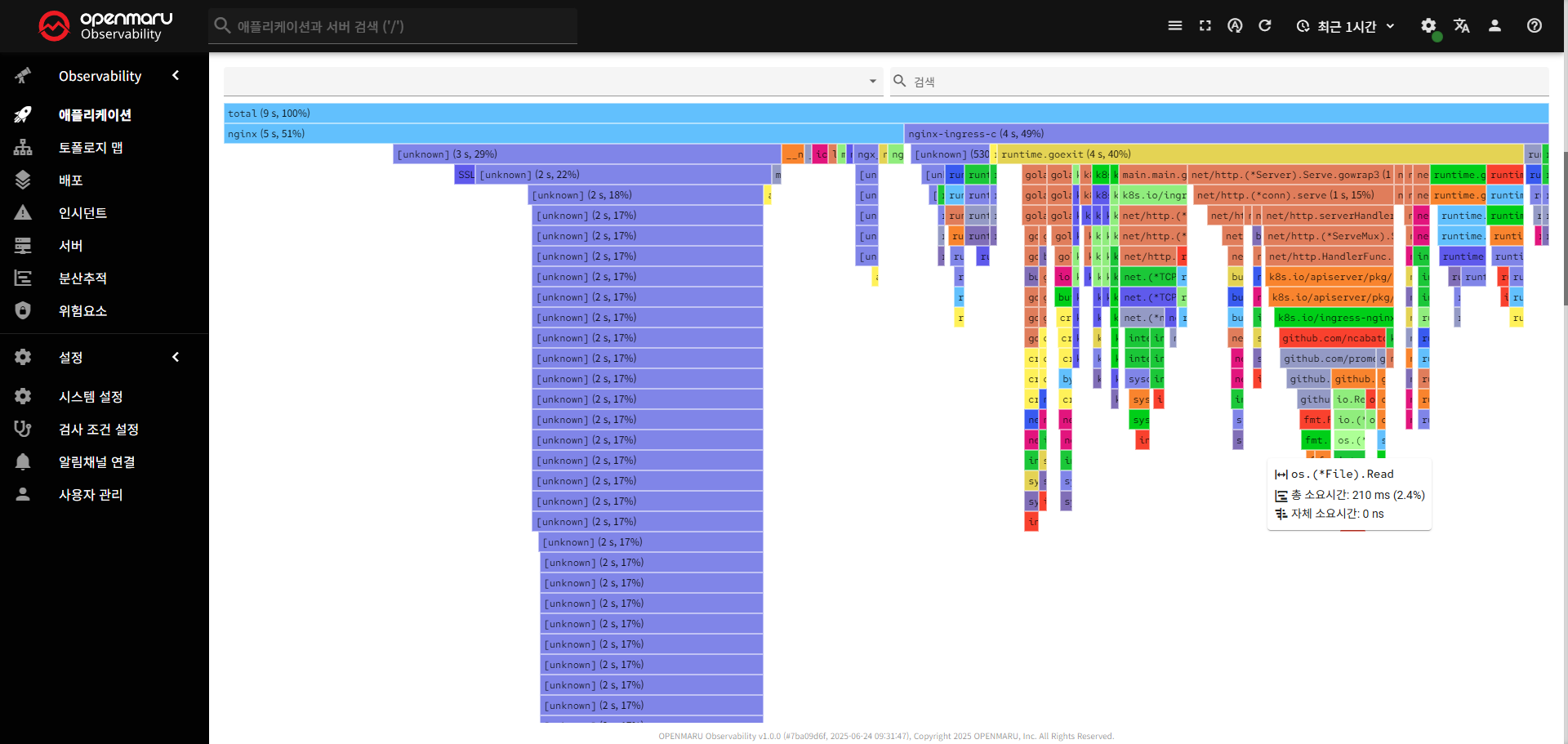
- 가로축 : 응답시간 ( 너비가 클수록 시간 소요 )
- 세로축 : 호출 스택 ( 깊이가 클수록 중첩 호출 )
- 노드 클릭 시 표시 정보
- 함수명
- 총 시간 : 해당 함수와 하위 함수들의 총 실행 시간
- 자체 소요시간 : 해당 함수만의 실행 시간 ( 하위 함수 제외 )
- 비율 : 전체 프로파일에서 차지하는 비율
분산 추적
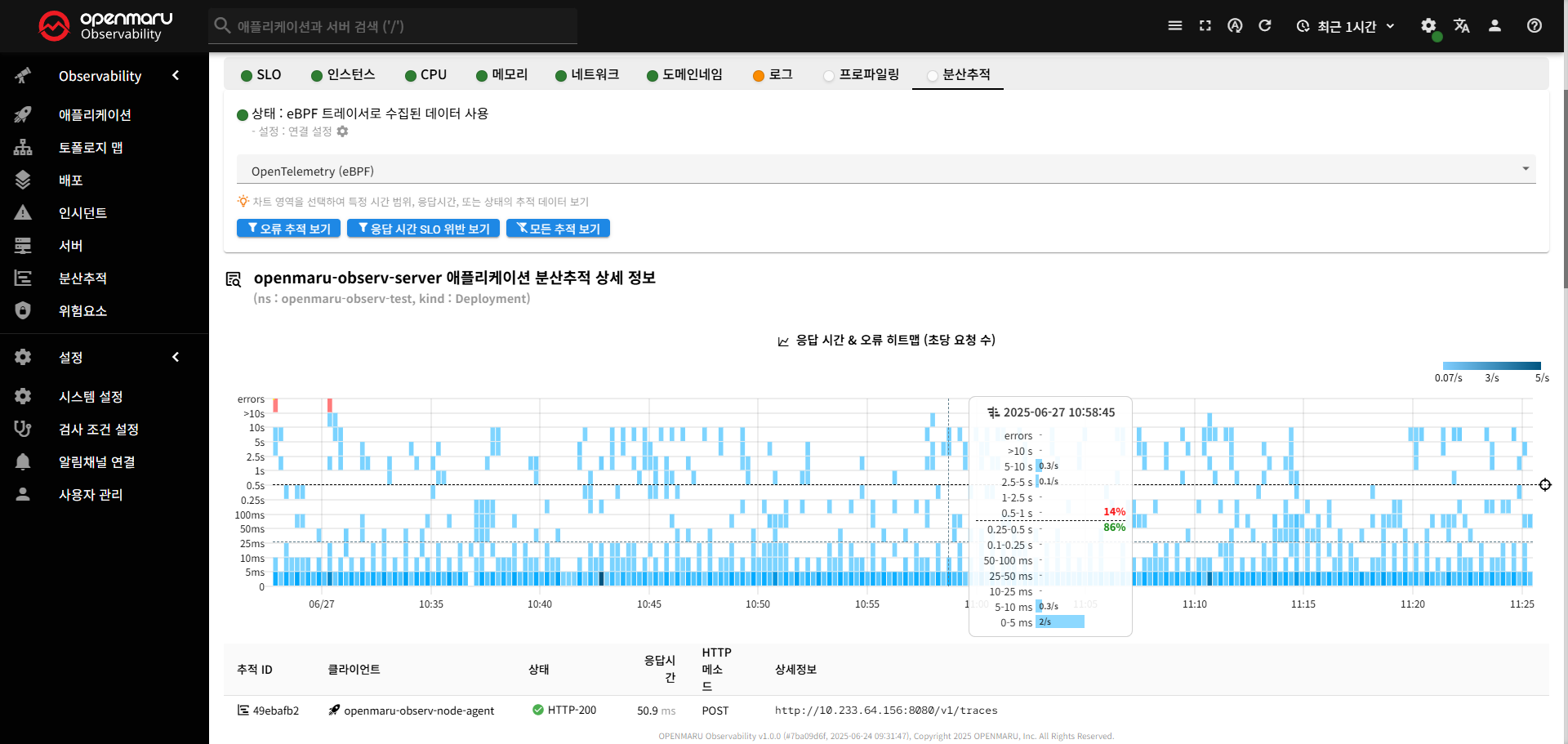
분산 추적 탭은 마이크로서비스 환경에서 요청이 여러 서비스를 거쳐 처리되는 과정을 시각적으로 추적하고 분석할 수 있는 기능을 제공합니다.
이 탭을 통해 요청의 흐름, 성능 병목, 오류 발생 지점 등을 정확히 파악할 수 있습니다.
필터링 기능
- 드롭다운 메뉴로 사용 가능한 프로파일 타입선택
- 설정 항목: 오류 추적 보기, 응답 시간 SLO, 모든 추적 보기
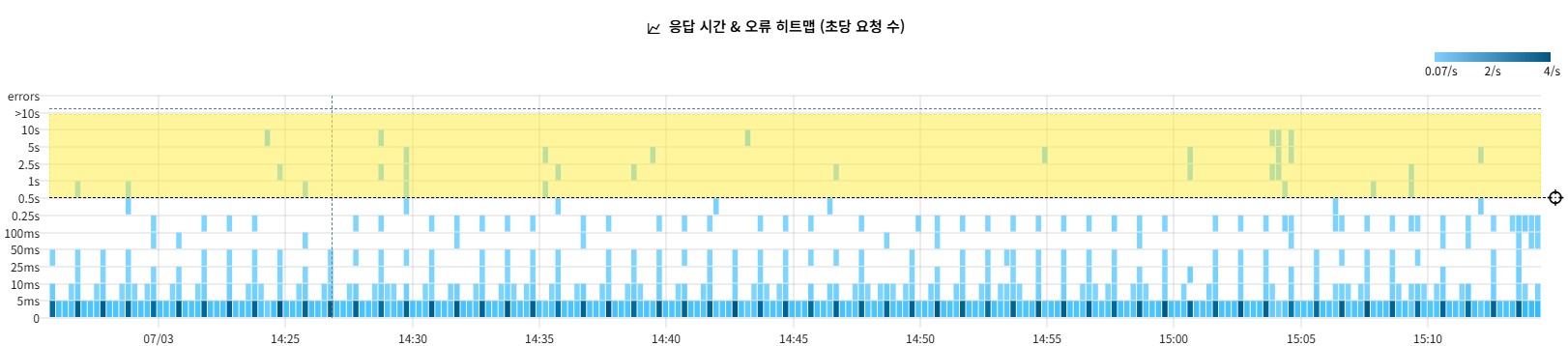
- 오류 추적 보기: 오류가 발생한 구간만 필터링
- 응답 시간 SLO: SLO 임계값을 초과한 구간만 필터링
- 모든 추적 보기: 모든 추적 데이터 표시 ( 필터 해제 )
추적 데이터 테이블
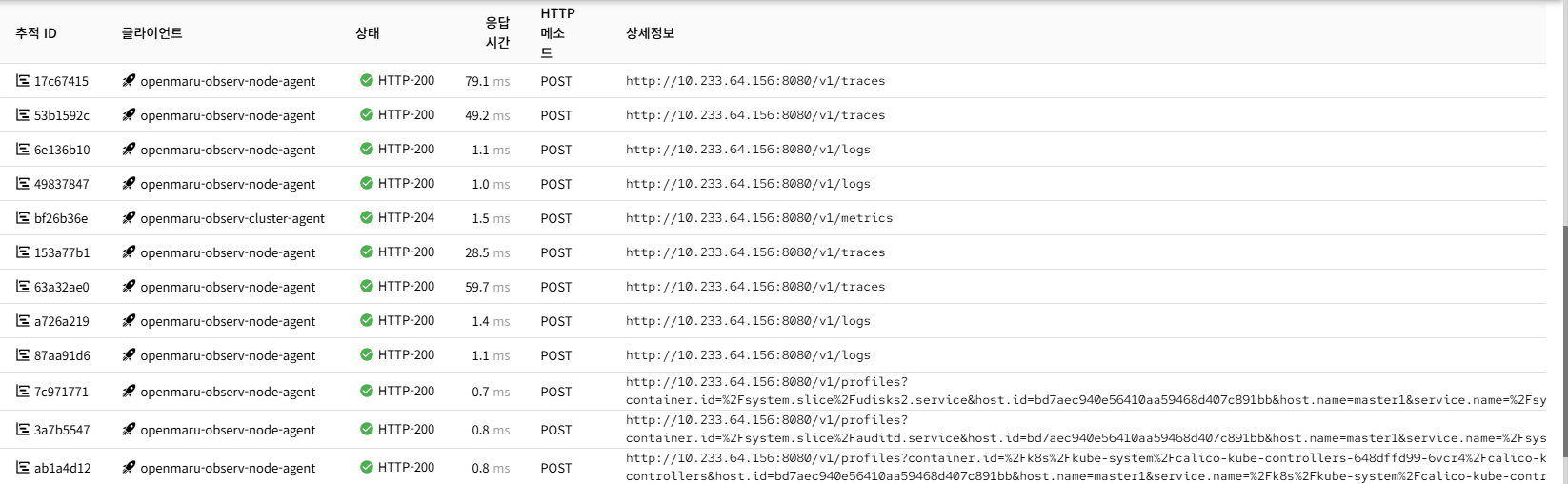
- 추적 ID: 각 추적의 고유 식별자 (8자리로 축약 표시)
- 클라이언트: 추적한 클라이언트 정보
- 상태: 추적의 성공/실패 상태 (아이콘으로 표시)
- 응답시간: 전체 추적의 소요 시간 (밀리초)
- HTTP 메소드: 요청의 HTTP 메소드
- 상세정보: 추가 메타데이터 정보 ( 테이블에서는 http.url 값만 표시 )
- 추적 상세 보기: 추적 ID 클릭 시 상세 추적 화면으로 이동
-
추적 상세 화면
- 시작 시간: 추적이 시작된 정확한 시간 (밀리초 단위)
- 응답시간: 전체 추적의 소요 시간
- 상태: 추적의 성공/실패 상태 및 메시지
-
추적 스팬
- 서비스 & 작업: 각 스팬의 서비스명과 작업명
- 시간축: 추적의 시간 흐름을 시각적으로 표시
- 스팬 바: 각 스팬의 실행 시간을 비례적으로 표시
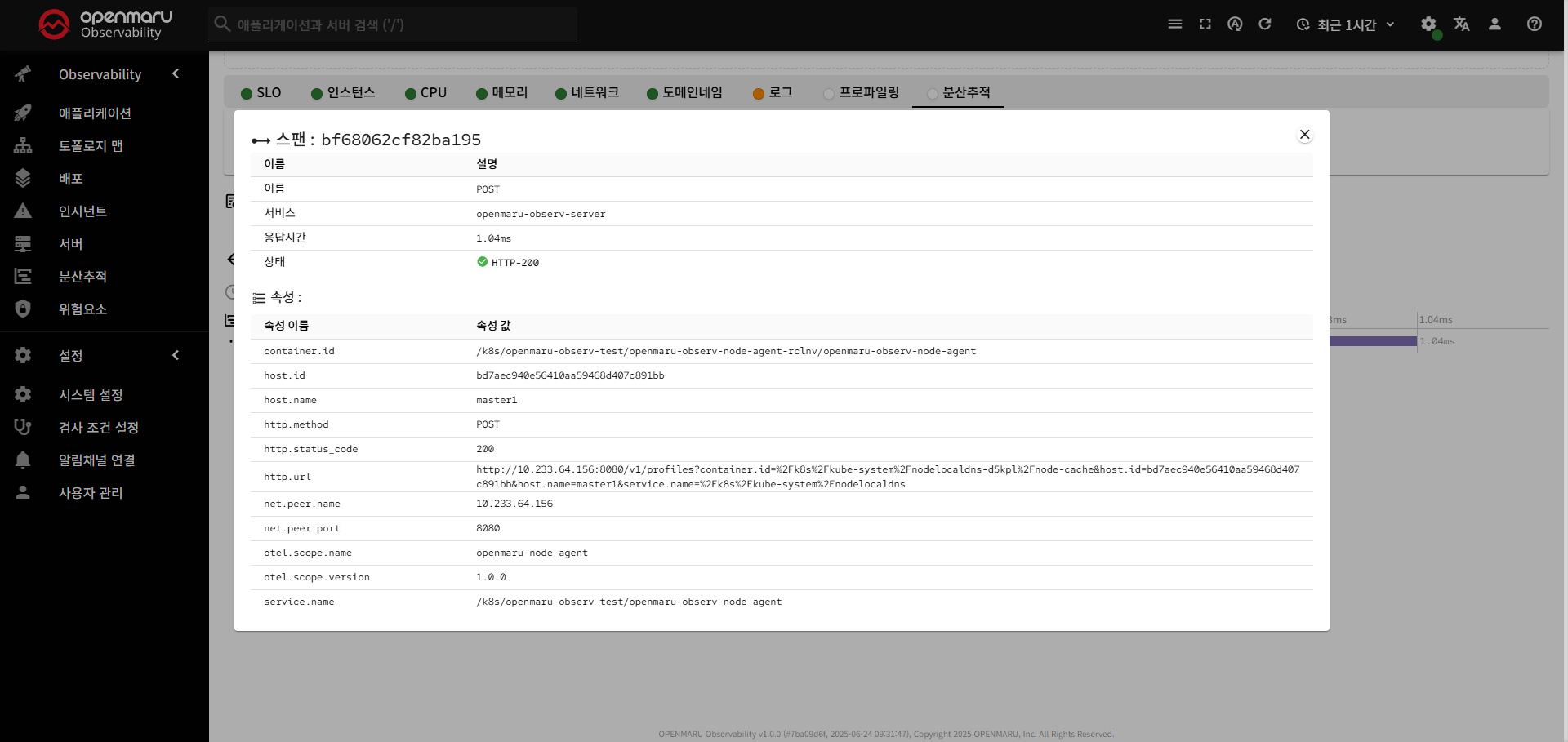
- 스팬 클릭 시 표시 정보
- 기본 정보: 스팬명, 서비스명, 시작/종료 시간, 지속 시간
- 속성: 스팬과 관련된 메타데이터 (HTTP 메소드, URL, 상태 코드 등)
- 이벤트: 스팬 내에서 발생한 특정 이벤트들
- 스택 트레이스: 오류 발생 시 스택 트레이스 정보