노드
COP Console의 노드 관리 기능을 사용하면 Kubernetes 클러스터를 구성하는 노드의 상태를 확인하고, 유지보수 작업을 수행할 수 있습니다. 사이드바에서 클러스터 > 노드를 선택하여 접근합니다.
노드 목록
노드 목록 화면에서는 클러스터에 속한 모든 노드의 현황을 한눈에 확인할 수 있습니다.
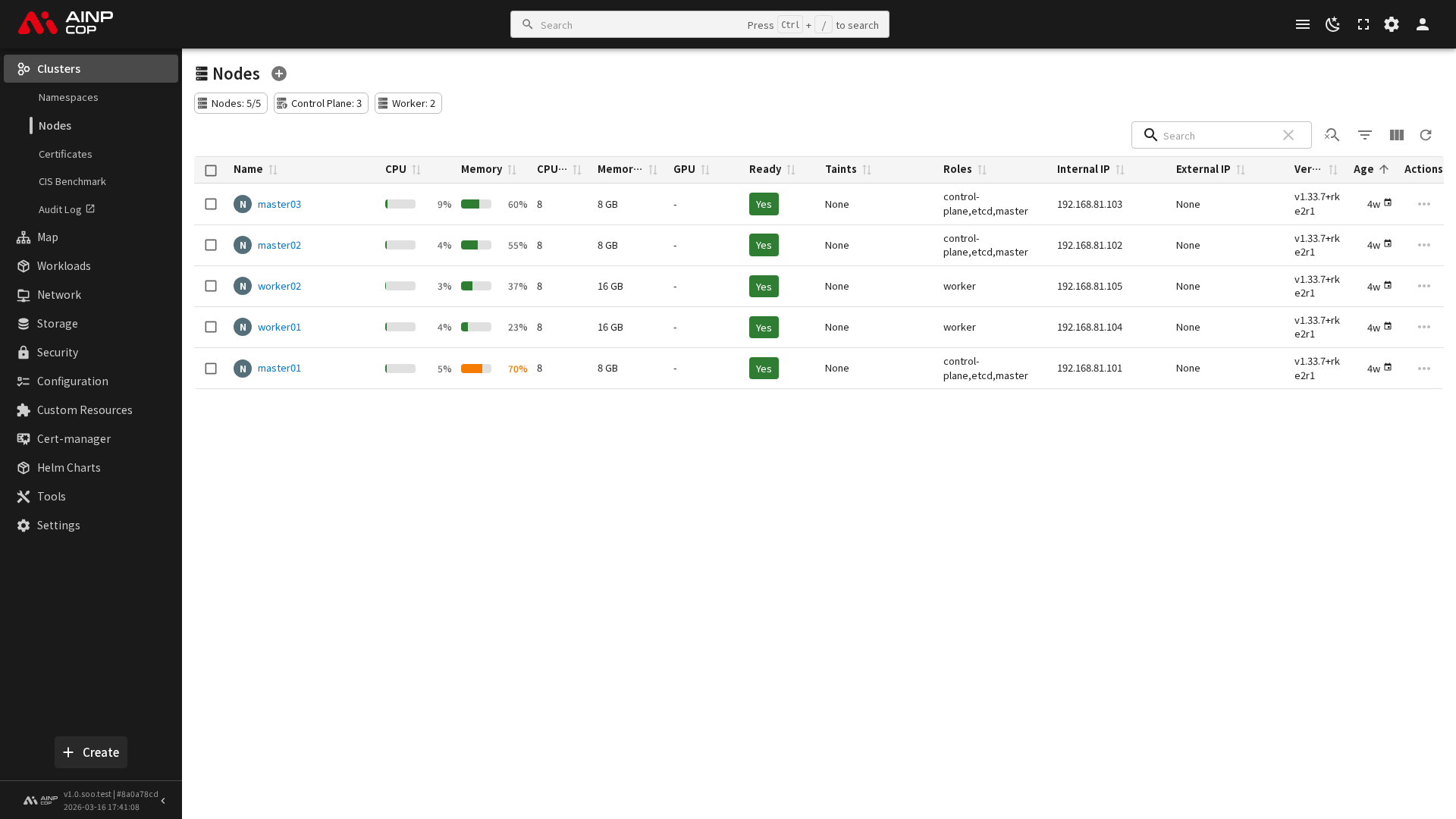
표시 항목
| 항목 | 설명 |
|---|---|
| 이름 | 노드의 호스트명 |
| 상태 | Ready, NotReady, SchedulingDisabled 등 |
| 역할 | control-plane, worker 등 |
| 버전 | Kubelet 버전 |
| CPU 사용률 | 현재 CPU 사용량 / 할당 가능 CPU |
| 메모리 사용률 | 현재 메모리 사용량 / 할당 가능 메모리 |
| Pod 수 | 해당 노드에서 실행 중인 Pod 수 |
| 생성 시간 | 노드가 클러스터에 등록된 시간 |
상태 표시
- Ready: 노드가 정상적으로 작동 중입니다. Pod 스케줄링이 가능합니다.
- NotReady: 노드에 문제가 발생하여 Pod 스케줄링이 불가능합니다.
- SchedulingDisabled: Cordon 처리되어 새로운 Pod이 스케줄링되지 않습니다.
GPU 탐지
노드에 GPU가 장착되어 있는 경우 목록에서 GPU 정보가 표시됩니다. NVIDIA, AMD, Intel GPU를 자동으로 탐지합니다.
노드 상세
노드 목록에서 특정 노드를 클릭하면 상세 페이지로 이동합니다. 상세 페이지는 여러 탭으로 구성되어 있습니다.
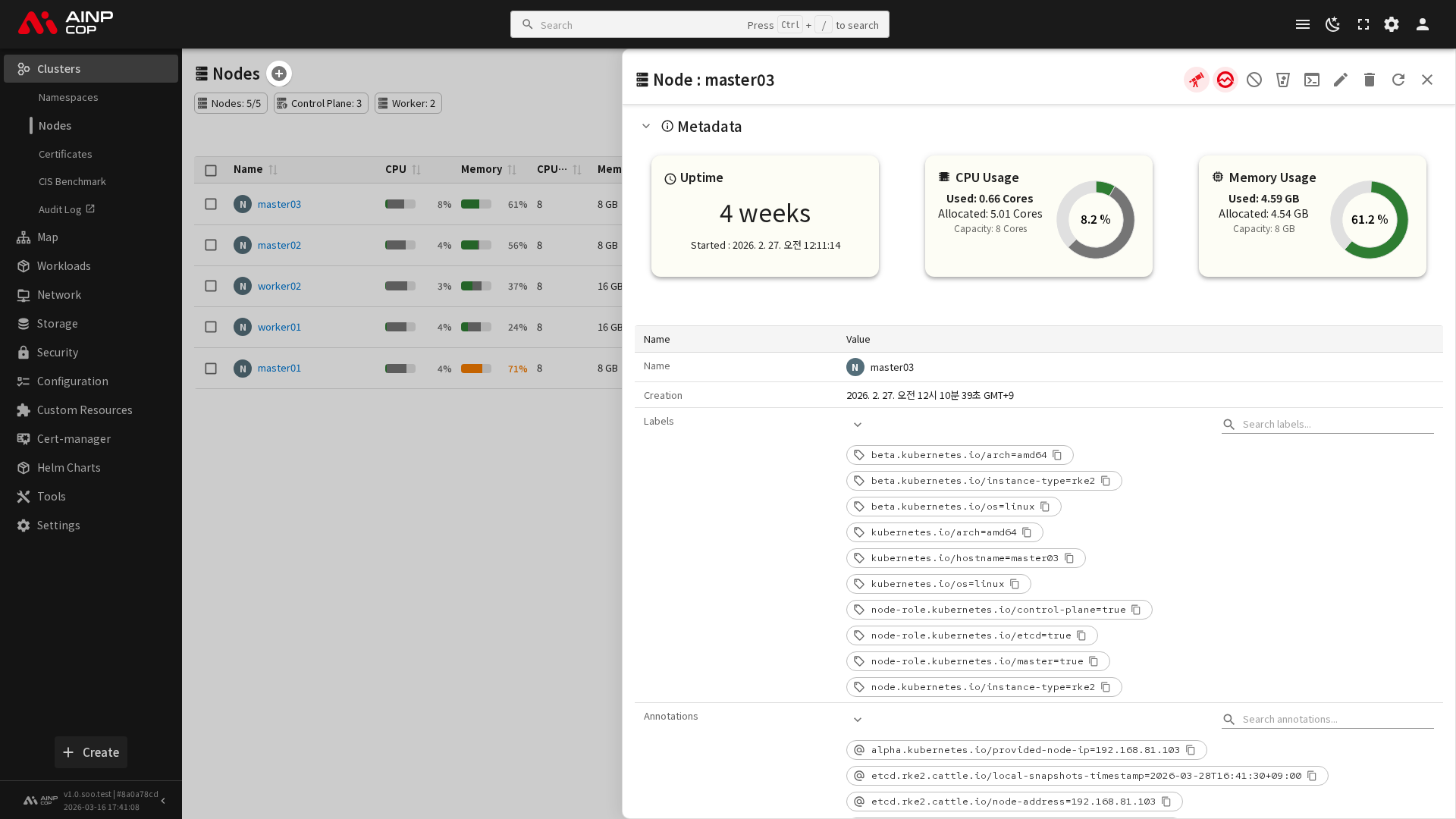
상세 페이지에서는 메타데이터(이름, 역할, 생성 시간), CPU/메모리/디스크 사용률 게이지 차트, 조건 목록, 시스템 정보, 실행 중인 Pod 목록 등을 확인할 수 있습니다.
조건 (Conditions)
노드의 현재 상태 조건을 표시합니다.
| 조건 | 설명 |
|---|---|
| Ready | 노드가 정상 동작 중인지 여부 |
| MemoryPressure | 노드의 메모리가 부족한 상태인지 여부 |
| DiskPressure | 노드의 디스크 용량이 부족한 상태인지 여부 |
| PIDPressure | 노드의 프로세스 ID가 부족한 상태인지 여부 |
| NetworkUnavailable | 노드의 네트워크가 정상인지 여부 |
각 조건은 True, False, Unknown 상태를 가지며, 비정상 상태인 경우 경고 아이콘이 표시됩니다.
시스템 정보
노드의 시스템 구성 정보를 표시합니다.
- 운영체제(OS): 노드에서 실행 중인 운영체제 (예: linux)
- OS 이미지: 운영체제 배포판 (예: Ubuntu 22.04 LTS)
- 커널 버전: Linux 커널 버전
- 컨테이너 런타임: 사용 중인 컨테이너 런타임 (예: containerd://1.7.x)
- Kubelet 버전: Kubelet의 버전
- Kube-Proxy 버전: Kube-Proxy의 버전
- 아키텍처: CPU 아키텍처 (예: amd64, arm64)
Pod 목록
해당 노드에서 실행 중인 모든 Pod의 목록을 표시합니다. 각 Pod의 네임스페이스, 상태, CPU/메모리 사용량을 확인할 수 있습니다. Pod를 클릭하면 Pod 상세 페이지로 이동합니다.
이벤트
해당 노드와 관련된 Kubernetes 이벤트 목록을 시간순으로 표시합니다. 노드 장애 진단 시 이벤트 내역을 확인하는 것이 유용합니다.
메트릭 차트
Observability 시스템이 연동되어 있는 경우 노드의 리소스 사용량을 차트로 확인할 수 있습니다.
- CPU 사용률: 시간대별 CPU 사용률 추이
- 메모리 사용률: 시간대별 메모리 사용률 추이
- 네트워크 I/O: 수신/송신 네트워크 트래픽
Cordon/Uncordon (스케줄링 비활성/활성)
Cordon은 노드에 새로운 Pod이 스케줄링되지 않도록 비활성화하는 작업입니다. 노드 유지보수 전에 수행합니다.
Cordon 수행
- 노드 목록 또는 상세 페이지에서 대상 노드를 선택합니다.
- Cordon 버튼을 클릭합니다.
- 확인 다이얼로그에서 확인을 클릭합니다.
- 노드 상태가
SchedulingDisabled로 변경됩니다.
Cordon 처리된 노드에서 이미 실행 중인 Pod은 영향을 받지 않습니다. 새로운 Pod만 해당 노드에 스케줄링되지 않습니다.
Uncordon 수행
- Cordon 상태인 노드를 선택합니다.
- Uncordon 버튼을 클릭합니다.
- 확인 다이얼로그에서 확인을 클릭합니다.
- 노드가 정상 스케줄링 가능 상태로 복원됩니다.
Drain (Pod 퇴거)
Drain은 노드에서 실행 중인 모든 Pod을 안전하게 다른 노드로 이동시키는 작업입니다. 노드 점검이나 업그레이드 시 사용합니다.
Drain 수행
- 노드 목록 또는 상세 페이지에서 대상 노드를 선택합니다.
- Drain 버튼을 클릭합니다.
- Drain 옵션을 설정합니다.
- 확인을 클릭하여 Drain을 시작합니다.
Drain 옵션
| 옵션 | 설명 |
|---|---|
| 빈 디렉토리 데이터 삭제 | emptyDir 볼륨의 데이터를 삭제합니다. 비활성화하면 emptyDir을 사용하는 Pod이 있는 경우 Drain이 실패합니다. |
| DaemonSet 무시 | DaemonSet으로 관리되는 Pod을 무시합니다. DaemonSet Pod은 모든 노드에서 실행되어야 하므로 일반적으로 이 옵션을 활성화합니다. |
| 강제 퇴거 | ReplicaSet, Job 등으로 관리되지 않는 독립 Pod도 강제로 퇴거합니다. 데이터 손실 위험이 있으므로 주의가 필요합니다. |
주의 사항
- Drain 전에 반드시 Cordon을 먼저 수행하시기 바랍니다. Drain 중에 새로운 Pod이 스케줄링되는 것을 방지합니다.
- Pod Disruption Budget(PDB)이 설정된 경우, PDB 조건을 만족하지 않으면 Drain이 지연될 수 있습니다.
- Drain이 완료된 후 유지보수가 끝나면 Uncordon을 수행하여 노드를 정상 상태로 복원하시기 바랍니다.
Node Shell (노드 쉘 접속)
COP Console에서 노드에 직접 쉘을 접속하여 명령어를 실행할 수 있습니다.
사용 방법
- 노드 상세 페이지에서 Node Shell 버튼을 클릭합니다.
- 웹 터미널이 열리며 노드에 쉘 세션이 연결됩니다.
- Linux 명령어를 직접 입력하여 노드 상태를 점검하거나 문제를 진단할 수 있습니다.
주의 사항
- Node Shell은 노드에 특권(privileged) 컨테이너를 생성하여 접속하는 방식입니다.
- 클러스터 관리자 권한이 필요합니다.
- 운영 환경에서는 주의하여 사용하시기 바랍니다. 잘못된 명령어 실행은 노드 장애를 유발할 수 있습니다.
- 쉘 세션이 종료되면 특권 컨테이너도 자동으로 정리됩니다.
GPU 노드
COP Console은 GPU가 장착된 노드를 자동으로 탐지하여 관련 정보를 표시합니다.
지원 GPU
| GPU 벤더 | 탐지 레이블 |
|---|---|
| NVIDIA | nvidia.com/gpu |
| AMD | amd.com/gpu |
| Intel | gpu.intel.com/i915 |
GPU 정보 표시
- 노드 목록에서 GPU 유무와 수량이 표시됩니다.
- 노드 상세 페이지에서 GPU 모델, 할당 가능 수량 등 상세 정보를 확인할 수 있습니다.
- GPU 리소스를 요청하는 Pod이 해당 노드에 스케줄링됩니다.
GPU 노드 관리는 머신러닝 워크로드나 GPU 가속이 필요한 애플리케이션을 운영할 때 유용합니다. GPU 리소스의 활용 현황을 모니터링하여 효율적인 리소스 배분이 가능합니다.