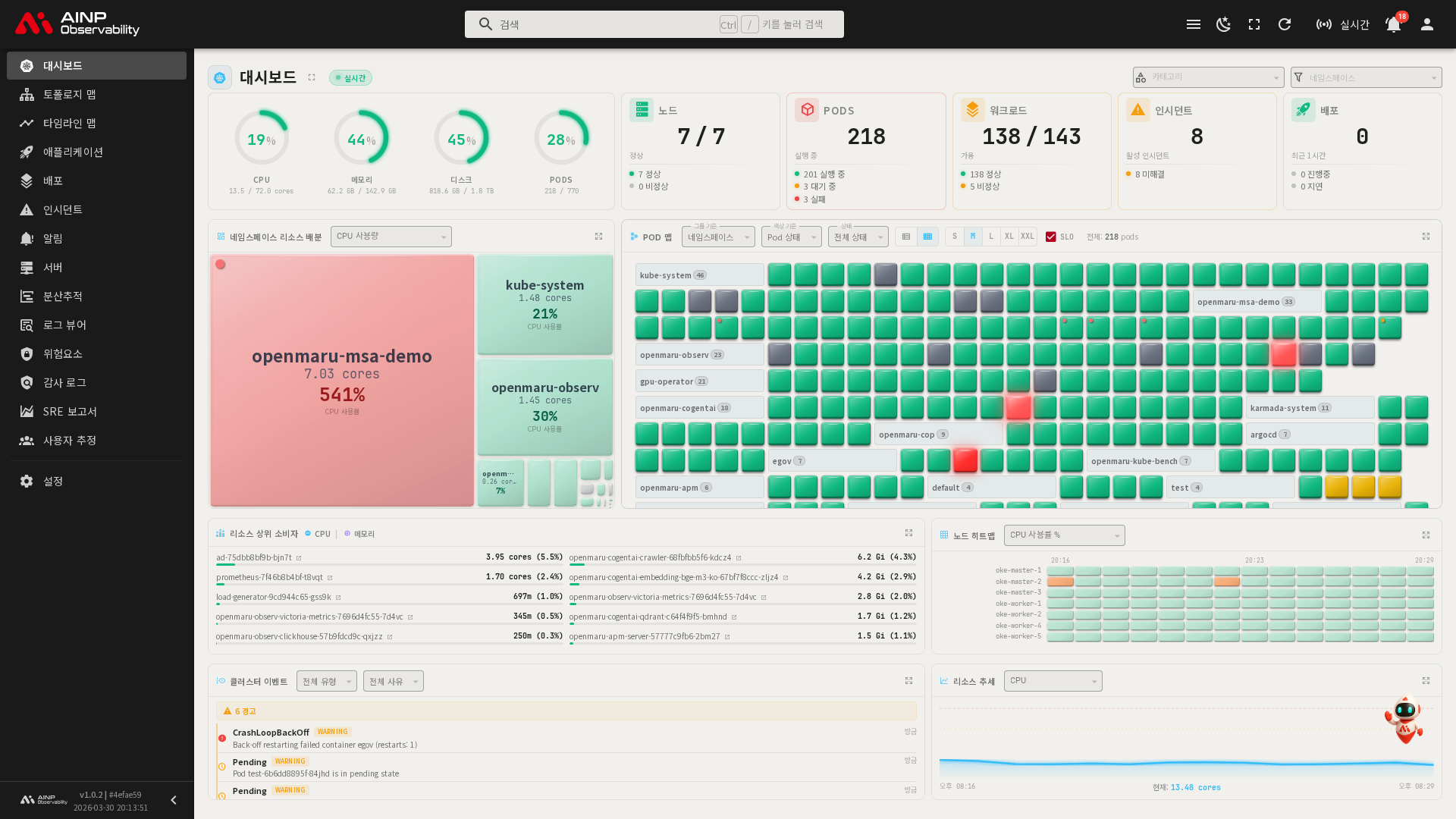
대시보드
Kubernetes 클러스터의 전체 현황을 실시간으로 한눈에 파악하는 화면입니다.
개요
대시보드는 모니터링 중인 Kubernetes 클러스터의 리소스 사용 상태, 워크로드(Workload) 상태, Pod 현황, 이��벤트 등을 실시간으로 보여주는 메인 화면입니다. 클러스터에 이상이 없는지 빠르게 확인하거나, 문제 발생 시 어느 영역에서 시작되었는지 파악하는 데 활용합니다.
좌측 사이드바에서 대시보드 메뉴를 클릭하면 진입할 수 있습니다. 대시보드는 실시간 전용 화면으로, 상단의 시간 선택기는 비활성화됩니다.
화면 구성
대시보드는 다음과 같은 영역으로 구성됩니다.
| 영역 | 설명 |
|---|---|
| 상단 헤더 | 실시간 모드 표시, 카테고리 필터, 네임스페이스 필터, 전체 화면 버튼 |
| 클러스터 리소스 게이지 | 클러스터 전체 CPU, 메모리, 디스크, Pod 사용 현황 |
| 클러스터 상태 카드 | 서버(노드), Pod, 워크로드, 인시던트, 배포의 현황 요약 |
| 네임스페이스 리소스 배분 | 네임스페이스별 리소스 사용 비중 트리맵 |
| Pod 맵 | 전체 Pod의 상태를 타일로 시각화 |
| 리소스 상위 소비자 | CPU, 메모리를 가장 많이 사용하는 워크로드 목록 |
| 노드 히트맵 | 서버(노드)별 리소스 사용률 히트맵 |
| 클러스터 이벤트 | 최근 발생한 Kubernetes 이벤트 목록 |
| 리소스 추세 | 시간대별 클러스터 리소스 사용량 추이 차트 |
주요 기능
실시간 모드
대시보드는 실시간 전용 화면입니다. 글로벌 헤더 우측의 시간 선택기가 ((•)) 실시간 모드로 표시되며, 시간 범위 선택이 비활성화됩니다. 서버와 WebSocket으로 연결되어 클러스터 데이터가 자동으로 갱신됩니다.
다른 화면(애플리케이션, SRE 보고서 등)으로 이동하면 시간 선택기가 시계 아이콘으로 바뀌며 조회 기간을 직접 선택할 수 있습니다. 대시보드로 돌아오면 다시 실시간 모드로 전환됩니다.
카테고리 및 네임스페이스 필터
대시보드 상단 헤더에서 카테고리와 네임스페이스를 선택하여 특정 범위의 리소스만 표시할 수 있습니다.
- 카테고리 필터: 드롭다운에서 카테고리를 선택하면, 해당 카테고리에 속하는 애플리케이션의 데이터만 대시보드에 표시됩니다. 클러스터 상태 카드, 네임스페이스 리소스 배분, Pod 맵, 리소스 상위 소비자 등 모든 영역이 선택한 카테고리 기준으로 갱신됩니다. X 버튼을 클릭하면 필터가 해제됩니다.
- 네임스페이스 필터: 특정 네임스페이스를 선택하면, 해당 네임스페이스의 데이터만 표시됩니다. 기본값은 전체 네임스페이스입니다.
참고: 네임스페이스(Namespace)는 Kubernetes에서 리소스를 논리적으로 구분하는 단위입니다.
클러스터 리소스 게이지
클러스터 전체의 리소스 사용 현황을 원형 게이지로 보여줍니다. 다음 네 가지 항목이 표시됩니다.
| 게이지 | 설명 |
|---|---|
| CPU | CPU 사용률(%). 현재 사용량 / 전체 용량 |
| Memory | 메모리 사용률(%). 현재 사용량 / 전체 용량 |
| Disk | 디스크 사용률(%). 현재 사용량 / 전체 용량 |
| Pods | Pod 사용 비율(%). 현재 Pod 수 / 최대 허용 Pod 수 |
각 게이지는 사용률에 따라 색상이 달라집니다.
| 색상 | 기준 | 의미 |
|---|---|---|
| 초록색 | 75% 미만 | 정상 |
| 노란색 | 75% 이상 90% 미만 | 주의 |
| 빨간색 | 90% 이상 | 위험 |
게이지 아래에는 현재 사용량과 전체 용량이 수치로 표시됩니다(예: 2.5 / 8.0 cores, 12.3 / 32.0 GB).
게이지 상세 툴팁
게이지 위에 마우스를 올리면 상세 툴팁이 나타나며, 다음 정보를 확인할 수 있습니다.
| 항목 | 설명 |
|---|---|
| Usage | 현재 사용량과 게이지 바 |
| Capacity | 전체 용량 |
| Available | 잔여 가용량 |
| Request | 요청량 (CPU, 메모리만 해당) |
| Limit | 제한량 (CPU, 메모리만 해당) |
클러스터 상태 카드
클러스터의 핵심 현황을 5개의 카드로 요약합니다. 각 카드를 클릭하면 관련 상세 화면으로 바로 이동할 수 있습니다.
| 카드 | 주요 수치 | 하위 항목 | 클릭 시 이동 |
|---|---|---|---|
| Nodes | Ready 수 / 전체 수 | Ready, NotReady | 서버 목록 |
| Pods | 전체 Pod 수 | Running, Pending, Failed | 토폴로지 맵 |
| Workloads | Available 수 / 전체 수 | Healthy, Unhealthy | 애플리케이션 목록 |
| Incidents | 활성 인시던트 수 | Unresolved | 인시던트 목록 |
| Deploys | 최근 1시간 배포 수 | In Progress, Stuck | 배포 목록 |
카드 테두리 색상은 상태에 따라 달라집니다.
- 기본 테두리: 문제가 없는 정상 상태
- 빨간색 테두리: NotReady 서버 또는 Failed/CrashLoop Pod가 있는 경우
- 노란색 테두리: Unhealthy 워크로드, 활성 인시던트, 또는 지연된 배포가 있는 경우
- 파란색 테두��리: 진행 중인 배포가 있는 경우
네임스페이스 리소스 배분
각 네임스페이스가 클러스터 자원을 얼마나 사용하고 있는지 트리맵으로 시각화합니다. 타일의 크기가 클수록 해당 네임스페이스의 자원 점유 비중이 높습니다.
메트릭 전환
패널 상단의 드롭다운에서 표시할 메트릭을 선택할 수 있습니다.
| 메트릭 | 타일 크기 기준 | 타일 내 표시 값 |
|---|---|---|
| SLO Status | 전체 SLO 수 | SLO 위반율 (Warning+Critical / 전체) |
| CPU Usage | CPU 사용량 | 사용량 / Request 비율 |
| Memory Usage | 메모리 사용량 | 사용량 / Request 비율 |
| Pod Count | Pod 수 | 네임스페이스별 Pod 수 |
타일 색상
CPU, Memory 메트릭 기준일 때 타일 색상은 Request 대비 사용률을 나타냅니다.
| 색상 | 기준 | 의미 |
|---|---|---|
| 초록색 | 75% 미만 | 정상 |
| 노란색 | 75% 이상 90% 미만 | 주의 |
| 빨간색 | 90% 이상 | 과다 사용 |
| 회색 | Request 미설정 | 사용률 표시 불가 (절대 사용량만 표시) |
SLO 메트릭 기준일 때는 SLO 위반율에 따라 초록(OK)/노란(Warning)/빨간(Critical)색으로 표시됩니다.
SLO 상태 표시점
타일 우측 상단에 작은 점이 표시될 수 있습니다. 이 점은 해당 네임스페이스 내 SLO 상태를 나타냅니다.
- 노란 점: SLO 경고 상태가 존재합니다.
- 빨간 점 (깜빡임): SLO 심각 상태가 존재합니다.
상세 툴팁
타일 위에 마우스를 올리면 상세 툴팁이 표시됩니다.
- 네임스페이스 이름과 사용률 뱃지
- Share: 전체 대비 해당 네임스페이스의 비중(%)
- 선택한 메트릭 값 (예: CPU 사용량, Pod 수)
- CPU 사용 현황: 현재 사용량과 게이지 바, Request/Limit 값
- 메모리 사용 현황: 현재 사용량과 게이지 바, Request/Limit 값
- Pod 수: 해당 네임스페이스의 Pod 수
- SLO 현황: SLO가 설정된 경우 OK/Warning/Critical 개수와 준수율
네임스페이스 클릭 필터링
트리맵에서 특정 네임스페이스 타일을 클릭하면 대시보드 전체가 해당 네임스페이스로 필터링됩니다.
- 클릭한 네임스페이스가 대시보드 상단의 네임스페이스 필터에 자동 설정됩니다.
- Pod 맵, 클러스터 상태 카드, 리소스 상위 소비자 등 대시보드의 모든 영역이 해당 네임스페이스 데이터만 표시합니다.
- 트리맵 패널 제목 옆에 선택된 네임스페이스명이 필터 칩 형태로 나타나며, Pod 맵 패널에도 동일한 필터 칩이 표시됩니다.
- 트리맵의 메트릭 설정에 따라 Pod 맵의 Color by 설정이 자동으로 연동됩니다. 예를 들어, 트리맵이 CPU Usage를 표시 중이면 Pod 맵의 색상 기준도 CPU Usage로 변경됩니다.
- 이미 선택된 네임스페이스를 다시 클릭하면 필터가 해제됩니다.
- 필터 칩의 X 버튼을 클릭하여 수동으로 해제할 수도 있습니다.
| 트리맵 메트릭 | Pod 맵 Color by 자동 연동 |
|---|---|
| CPU Usage | CPU Usage |
| Memory Usage | Memory Usage |
| Pod Count | Pod Status |
| SLO Status | SLO Status |
확장 보기의 리소스 효율 분석
패널을 확장하면 트리맵 하단에 리소스 효율 분석이 추가로 표시됩니다. 네임스페이스��를 선택한 경우 해당 네임스페이스의 CPU/메모리 Request, Limit, 사용량을 비교 분석할 수 있으며, 선택하지 않은 경우 전체 네임스페이스 합산 데이터가 표시됩니다.
효율성 상태 판정 기준:
| 상태 | 뱃지 색상 | 기준 | 설명 |
|---|---|---|---|
| 과잉 할당 (Over-provisioned) | 노란색 | 사용량이 Request의 40% 미만 | 할당된 자원이 필요량보다 많아 낭비가 발생합니다. Request를 줄이면 클러스터 자원을 더 효율적으로 활용할 수 있습니다. |
| 적정 (Optimal) | 초록색 | 사용량이 Request의 40~90% | 자원이 효율적으로 활용되고 있으며, 여유분도 적절히 확보되어 있습니다. |
| 과부하 (Over-utilized) | 빨간색 | 사용량이 Request의 90% 초과 | 자원이 부족하여 성능 저하나 OOM(Out of Memory) 등의 문제가 발생할 수 있습니다. Request와 Limit를 늘리는 것을 권장합니다. |
| Request 미설정 (No Request) | 회색 | Request가 설정되지 않음 | 효율성 판정이 불가하며, 실제 사용량만 표시됩니다. |
불릿 차트(Bullet Chart) 구성:
CPU와 메모리 각각에 대해 다음 요소로 구성된 불릿 차트가 표시됩니다.
- 배경 바: Limit 전체 범위를 나타냅니다.
- Request 영역: Limit 대비 Request 비율을 반투명 영역으로 표시합니다.
- 실제 사용량 바: 현재 사용량을 색상 바로 표시합니다. 색상은 효율성 상태에 따라 달라집니다(초록: 적정, 노란: 과잉 할당, 빨간: 과부하).
- Request 마커: Request 지점에 세로선이 표시되어 실제 사용량과 Request의 비교가 직관적으로 가능합니�다.
차트 하단에는 Request, 실제 사용량(Actual), Limit 수치가 표시됩니다. Request가 설정된 경우 실제 사용량 옆에 Request 대비 백분율이 함께 표시됩니다.
효율성 뱃지 상세 툴팁:
효율성 상태 뱃지 위에 마우스를 올리면 상세 툴팁이 나타나며, 다음 정보를 확인할 수 있습니다.
- 효율성 상태와 백분율
- 산출 공식: Usage / Request x 100
- 실제 계산 값: 구체적인 사용량과 Request 값을 대입한 계산 결과
- 상태 설명: 현재 효율성 상태에 대한 안내 및 권장 조치
Pod 맵
클러스터 내 전체 Pod를 작은 타일로 표시하여 상태를 한눈에 파악할 수 있습니다. 각 Pod는 하나의 타일로 표현되며, 타일의 색상이 Pod의 상태나 리소스 사용량을 나타냅니다. 문제가 있는 Pod(Failed, CrashLoop, 사용률 90% 초과 등)의 타일은 깜빡임 애니메이션으로 주의를 끌어 빠르게 식별할 수 있습니다.
Pod 맵 컨트롤 옵션
Pod 맵 상단의 컨트롤 바에서 다양한 표시 옵션을 설정할 수 있습니다.
Group by (그룹 기준)
Pod를 어떤 기준으로 그룹화할지 선택합니다.
| 옵션 | 설명 |
|---|---|
| Namespace | 네임스페이스별로 그룹화 (기본값) |
| Node | 서버(노드)별로 그룹화 |
| Workload | 워크로드(Deployment, StatefulSet 등)별로 그룹화 |
| Pod Status | Pod 상태별로 그룹화 (crashloop, failed, pending 순으로 정렬) |
| SLO Status | SLO 상태별로 그룹화 (Critical, Warning, OK, N/A 순으로 정렬) |
Color by (색상 기준)
타일 색상이 나타내는 지표를 선택합니다.
| 옵션 | 색상 의미 |
|---|---|
| SLO Status | 초록(OK), 노란(Warning), 빨간(Critical), 회색(N/A) |
| CPU Usage | 초록(0 |
| Memory Usage | 초록(0 |
| Pod Status | Pod 상태별 고정 색상 (아래 범례 참조) |
| Restart Count | 초록(0회), 노란(1~3회), 빨간(3회 초과, 깜빡임) |
Pod Status 색상 범례:
| 색상 | 상태 | 설명 |
|---|---|---|
| 초록 | Running | 정상 실행 중 |
| 노란 | Pending | 스케줄 대기 중 |
| 빨간 (깜빡임) | Failed | 실패 상태 |
| 진한 빨간 (깜빡임) | CrashLoop | 반복 비정상 종료 |
| 회색 | Succeeded | 완료됨 |
| 연한 회색 | Evicted | 축출됨 |
| 투명 | Unknown | 알 수 없음 |
Status (상태 필터)
특정 상태의 Pod만 표시하도록 필터링합니다.
| ��옵션 | 설명 |
|---|---|
| All Statuses | 모든 Pod 표시 (기본값) |
| Running | 실행 중인 Pod만 표시 |
| Pending | 대기 중인 Pod만 표시 |
| Failed | 실패 상태의 Pod만 표시 |
| CrashLoop | 반복 비정상 종료 상태의 Pod만 표시 |
| Succeeded | 완료된 Pod만 표시 |
| Evicted | 축출된 Pod만 표시 |
레이아웃 전환
두 가지 레이아웃 중 하나를 선택할 수 있습니다.
- Flow 뷰 (기본값): 그리드 형태로 Pod 타일이 촘촘히 배치됩니다. 그룹 이름은 태그 형태로 타일 사이에 인라인 표시됩니다. 공간을 효율적으로 사용하므로 Pod 수가 많을 때 적합합니다.
- Grouped 뷰: 그룹별로 구분선과 헤더가 표시되며, 각 그룹 내에서 타일이 배치됩니다. 그룹 간 구분이 명확하여 비교가 쉽습니다.
타일 크기
타일 크기를 S, M, L, XL, XXL 중 선택할 수 있습니다. Pod 수가 많은 경우 S 또는 M을 사용하면 전체를 조망하기 쉽고, 개별 Pod를 자세히 보려면 XL 또는 XXL을 선택합니다.
SLO 오버레이
Color by 설정이 SLO Status가 아닌 경우에도 SLO 체크박스를 활성화하면 각 Pod 타일 위에 SLO 위반 상태를 오버레이로 표시할 수 있습니다. SLO Warning은 노란 점, SLO Critical은 빨간 점으로 타일 위에 나타납니다. 기본적으로 활성화되어 있으며, 체크를 해제하면 오버레이가 숨겨집니다.
컨트롤 바 우측에는 현재 필터 조건에 맞는 총 Pod 수가 표시됩니다.
Pod 타일 팝업
개별 Pod 타일 위에 마우스를 올리면 상세 팝업(툴팁)이 나타나며, 다음 정보를 확인할 수 있습니다.
- Pod 이름과 상태 뱃지 (Running, Pending, Failed, CrashLoop, Succeeded, Evicted, Unknown)
- 네임스페이스 / 서버(노드) 이름
- CPU 사용률: Request가 설정된 경우 Request 대비 사용 비율 게이지, 미설정 시 절대 사용량 표시
- 메모리 사용률: Request가 설정된 경우 Request 대비 사용 비율 게이지, 미설정 시 절대 사용량 표시
- SLO 상태: 해당 Pod가 속한 애플리케이션의 SLO 상태(OK/Warning/Critical), 가용성 목표, 응답 시간 P99 값
- 재시작 횟수와 Pod 가동 시간(Age)
- 워크로드 정보: 소속 워크로드 종류(Deployment, StatefulSet 등)와 이름
Pod 타일 클릭
Pod 타일을 클릭하면 해당 Pod가 속한 애플리케이션 상세 팝업이 표시됩니다. 이 팝업에서 애플리케이션의 메트릭과 상세 정보를 대시보드를 떠나지 않고 바로 확인할 수 있습니다.
그룹 이름 클릭
Group by가 Namespace로 설정된 경우, 그룹 이름(네임스페이스명)을 클릭하면 해당 네임스페이스의 토폴로지 맵 화면으로 이동합니다.
확장 보기의 범례
Pod 맵을 확장하면 하단에 현재 Color by 설정에 맞는 색상 범례가 표시됩니다. 각 색상이 의미하는 상태 또는 수치 범위를 확인할 수 있어, 색상만으로 Pod 상태를 빠르게 파악하는 데 도움이 됩니다.
리소스 상위 소비자
CPU와 메모리를 가장 많이 사용하는 워크로드를 목록으로 보여줍니다. 클러스터 내에서 자원을 집중적으로 소비하는 애플리케이션을 빠르게 파악하는 데 유용합니다.
- 기본 보기에서는 CPU와 메모리 상위 소비자 각 5개를 나란히 표시합니다.
- 확장 보기에서는 CPU 상위 소비자와 메모리 상위 소비자 목록을 각각 최대 20개까지 확인할 수 있습니다.
- 목록에서 애플리케이션을 클릭하면 해당 애플리케이션의 상세 정보를 팝업으로 확인할 수 있습니다.
노드 히트맵
클러스터를 구성하는 서버(노��드)들의 리소스 사용률을 히트맵 형태로 보여줍니다. 색상이 진할수록 사용률이 높습니다.
- 패널 우측 드롭다운에서 CPU Usage % 또는 Memory Usage % 중 표시할 메트릭을 선택할 수 있습니다.
- 특정 서버(노드) 셀을 클릭하면 해당 서버의 상세 정보를 팝업으로 확인할 수 있습니다.
클러스터 이벤트
Kubernetes 클러스터에서 발생한 이벤트를 시간순으로 표시합니다. Pod 장애, 리소스 부족, 배포 등 운영 중 발생하는 주요 이벤트를 여기서 확인할 수 있습니다.
이벤트 유형:
- WARNING (경고): 주의가 필요한 이벤트입니다. Pod 장애, 리소스 부족, 스케줄링 실패 등 문제 상황을 나타냅니다.
- NORMAL (정상): 일반적인 운영 이벤트입니다. 배포, 스케일링, Pod 시작 등을 나타냅니다.
주요 이벤트 사유:
| 사유 | 유형 | 설명 |
|---|---|---|
| CrashLoopBackOff | WARNING | 컨테이너가 반복적으로 비정상 종료되어 재시작되고 있습니다. |
| OOMKilled | WARNING | 컨테이너가 메모리 한도(Limit)를 초과하여 강제 종료되었습니다. |
| Pending | WARNING | Pod가 서버(노드)에 스케줄되지 못하고 대기 중입니다. 리소스 부족이나 서버 조건 불충족이 원인일 수 있습니다. |
| Failed / Evicted | WARNING | Pod가 실패했거나 서버 리소스 압박으로 축출되었습니다. |
| InstanceDown | WARNING | 인스턴스가 다운되어 서비스에 영향을 줄 수 있습니다. |
| ScalingReplicaSet | NORMAL | Deployment가 ReplicaSet을 스케일링하고 있습니다. 배포 또는 오토스케일링 동작입니다. |
| Started | NORMAL | 인스턴스가 정상적으로 시작되었습니다. |
| Switchover | NORMAL | 데이터베이스 등의 Primary/Replica 전환이 수행되었습니다. |
참고: 배포, 인스턴스 Up/Down, Switchover 등 운영 이벤트는 최근 15분 이내 발생한 이벤트가 표시됩니다. CrashLoopBackOff, OOMKilled, Pending, Failed 등 Pod 상태 이벤트는 현재 시점의 클러스터 상태를 기준으로 표시됩니다. 최신순으로 최대 200개까지 표시되며, 기본 보기에서는 WARNING 이벤트가 우선 표시됩니다.
이벤트 타임라인 필터링
패널 상단에 두 개의 필터 드롭다운이 제공됩니다.
| 필터 | 옵션 | 설명 |
|---|---|---|
| 이벤트 유형 | All Types / Warning / Normal | 이벤트 유형별로 필터링합니다. |
| 이벤트 사유 | All Reasons / (동적 목록) | 현재 이벤트에 존재하는 사유 목록이 동적으로 생성되어 표시됩니다. 특정 사유(예: CrashLoopBackOff, OOMKilled)만 선별하여 확인할 수 있습니다. |
두 필터를 조합하여 사용할 수 있습니다. 예를 들어 유형을 "Warning"으로, 사유를 "OOMKilled"로 설정하��면 메모리 초과로 인한 경고 이벤트만 표시됩니다.
기본 보기에서는 WARNING 이벤트가 우선 정렬되어 최대 5개까지 표시되며, 이벤트가 더 있는 경우 "+N more events" 링크를 클릭하여 확장 보기로 전환할 수 있습니다.
확장 보기에서는 필터링된 전체 이벤트 목록과 함께 이벤트 안내 패널이 표시되어 각 이벤트 사유에 대한 설명을 참고할 수 있습니다.
리소스 추세
시간에 따른 클러스터 리소스 사용량 변화를 차트로 보여줍니다. 패널 우측 드롭다운에서 CPU 또는 Memory 중 표시할 메트릭을 선택할 수 있습니다.
전체 화면 모드
대시보드 제목 옆의 전체 화면 버튼을 클릭하면 사이드바 없이 브라우저 전체 화면으로 전환되어 더 넓게 볼 수 있습니다. 다시 클릭하거나 Esc 키를 눌러 일반 화면으로 돌아올 수 있습니다.
팁: 팀 공용 모니터에 대시보드를 전체 화면으로 표시해 두면 클러스터 현황을 상시 모니터링할 수 있습니다.
패널 확장 보기
각 패널 우측 상��단의 확장 보기 버튼을 클릭하면 해당 패널만 큰 화면으로 볼 수 있습니다. 확장 보기에서는 더 많은 데이터와 상세 정보가 표시됩니다.
| 패널 | 확장 보기에서 추가되는 내용 |
|---|---|
| 네임스페이스 리소스 배분 | 리소스 효율 분석 패널 |
| Pod 맵 | 색상 범례 |
| 리소스 상위 소비자 | 상위 20개까지 확장 |
| 클러스터 이벤트 | 이벤트 안내 패널 |
설정 유지
대시보드에서 변경한 설정값은 브라우저에 자동 저장됩니다. 다음에 대시보드에 접속하면 이전에 설정한 상태가 유지됩니다. 자동 저장되는 설정은 다음과 같습니다.
- 카테고리 필터
- Pod 맵: Group by, Color by, Status 필터, 레이아웃, 타일 크기, SLO 오버레이
- 네임스페이스 리소스 배분 메트릭
- 노드 히트맵 메트릭
- 클러스터 이벤트 필터
- 리소스 추세 메트릭