애플리케이션
모니터링 중인 애플리케이션의 전체 목록을 조회하고, 개별 애플리케이션의 상세 관측 데이터를 분석합니다.
개요
애플리케이션 메뉴는 Observability가 모니터링하는 모든 �애플리케이션(Application)을 한눈에 보여주는 화면입니다. 애플리케이션은 모니터링의 기본 단위로, Kubernetes 환경에서는 Deployment, StatefulSet, DaemonSet 등의 워크로드가 이에 해당합니다.
각 애플리케이션의 현재 상태와 주요 지표를 빠르게 파악하고, 특정 애플리케이션을 클릭하면 SLO(Service Level Objective, 서비스 수준 목표), CPU, 메모리, 로그(Log), 분산추적, 프로파일링(Profiling) 등 다양한 상세 리포트를 확인할 수 있습니다.
좌측 사이드바에서 애플리케이션 메뉴를 클릭하면 이 화면으로 이동합니다.
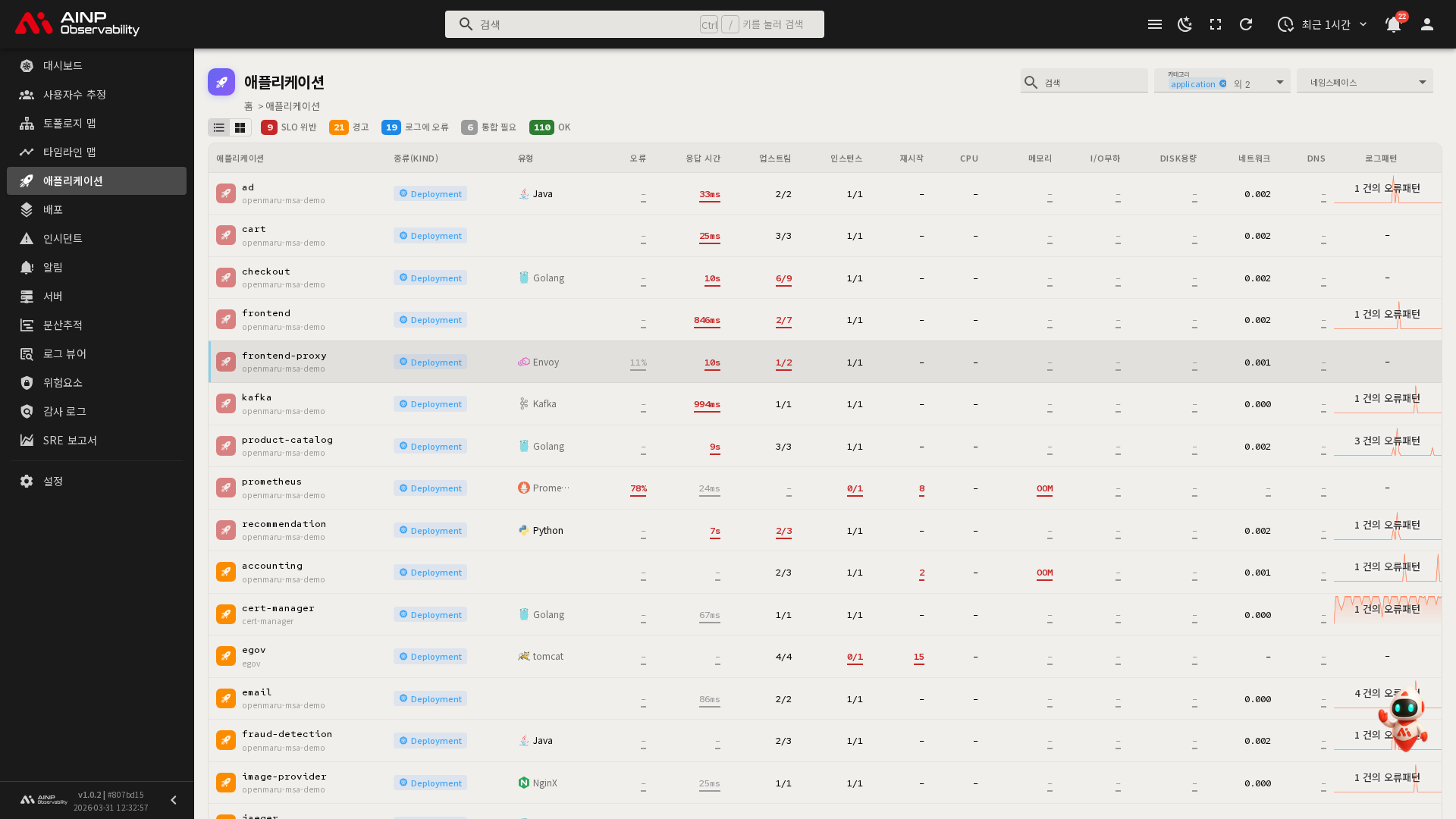
애플리케이션 목록
화면 구성
목록 화면 상단에는 필터와 뷰 전환 버튼, 상태 범례가 있으며, 아래에 애플리케이션 목록이 표시됩니다.
| 영역 | 설명 |
|---|---|
| 상단 헤더 | 페이지 제목, 애플리케이션 필터(네임스페이스, 카테고리, 검색) |
| 뷰 전환 토글 | 리스트 뷰(List View)와 카드 뷰(Card View) 전환 |
| 상태 범례 | 상태별 애플리케이션 수 표시 및 필터 |
| 목록 영역 | 리스트 뷰: 테이블 형태 / 카드 뷰: 카드 그리드 형태 |
| 페이지네이션 | 페이지당 표시 개수(10, 20, 50, 100, All)와 페이지 이동 |
상태 범례
화면 상단 툴바의 상태 범례에서는 전체 애플리케이션을 상태별로 요약해 보여줍니다.
| 상태 | 의미 |
|---|---|
| SLO 위반 | SLO 임계값(Threshold)을 초과한 애플리케이션. 즉각 조치가 필요합니다. |
| 경고 | 주의가 필요한 경고(Warning) 상태의 애플리케이션 |
| 로그에 오류 | 로그에 오류 패턴이 감지된 애플리케이션 |
| 통합 필요 | 에이전트 연결이 되지 않아 데이터가 수집되지 않는 애플리케이션 |
| OK | 정상 동작 중인 애플리케이션 |
상태 범례의 항목을 클릭하면 해당 상태의 애플리케이션만 필터링하여 볼 수 있습니다. 여러 상태를 동시에 선택할 수도 있으며, 선택된 항목은 강조 표시되고 나머지는 흐리게 표시됩니다. 다시 클릭하면 필터가 해제됩니다.
팁: SLO 위반이나 경고 상태의 애플리케이션 수를 먼저 확인하고, 해당 상태를 클릭해 문제가 있는 애플리케이션만 집중적으로 살펴보세요.
주요 기능
필터
화면 우측 상단의 필터를 사용해 네임스페이스(Namespace), 카테�고리, 애플리케이션 이름으로 목록을 좁힐 수 있습니다. 여러 조건을 조합하여 원하는 애플리케이션만 표시할 수 있습니다.
리스트 뷰
툴바 좌측의 뷰 전환 버튼에서 리스트 아이콘을 클릭하면 리스트 뷰로 전환됩니다. 리스트 뷰는 많은 애플리케이션을 한 번에 비교하기에 적합합니다.
각 열 헤더를 클릭하여 원하는 기준으로 정렬할 수 있으며, 여러 열을 순차적으로 클릭하여 다중 정렬도 가능합니다.
리스트 뷰의 주요 컬럼은 다음과 같습니다.
| 컬럼 | 설명 |
|---|---|
| 애플리케이션 | 이름과 네임스페이스. 클릭하면 상세 페이지로 이동합니다. |
| 종류(Kind) | Kubernetes 워크로드 종류 (Deployment, StatefulSet, DaemonSet 등) |
| 유형 | 애플리케이션 기술 스택 (Java, Python, Redis, Kafka 등) |
| 오류 | SLO 기준 오류율 |
| 응답 시간 | SLO 기준 응답 시간 |
| 업스트림 | 이 애플리케이션이 호출하는 업스트림(Upstream) 서비스 수 |
| 인스턴스 | 실행 중인 인스턴스(Instance) 수 |
| 재시작 | 인스턴스 재시작 횟수 |
| CPU | CPU 사용률 |
| 메모리 | 메모리 사용량 |
| I/O 부하 | 디스크 I/O 부하 |
| Disk 용량 | 디스크 사용량 |
| 네트워크 | 네트워크 상태 |
| DNS | DNS 쿼리 상태 |
| 로그패턴 | 최근 로그 오류 패턴 수와 추이 차트 |
참고: 오류, 응답 시간 등 지표가 빨간색 또는 주황색으로 강조된 경우, 해당 항목이 검사(Inspection) 임계값을 초과했음을 나타냅니다. 해당 값을 클릭하면 관련 상세 탭으로 바로 이동합니다.
카드 뷰
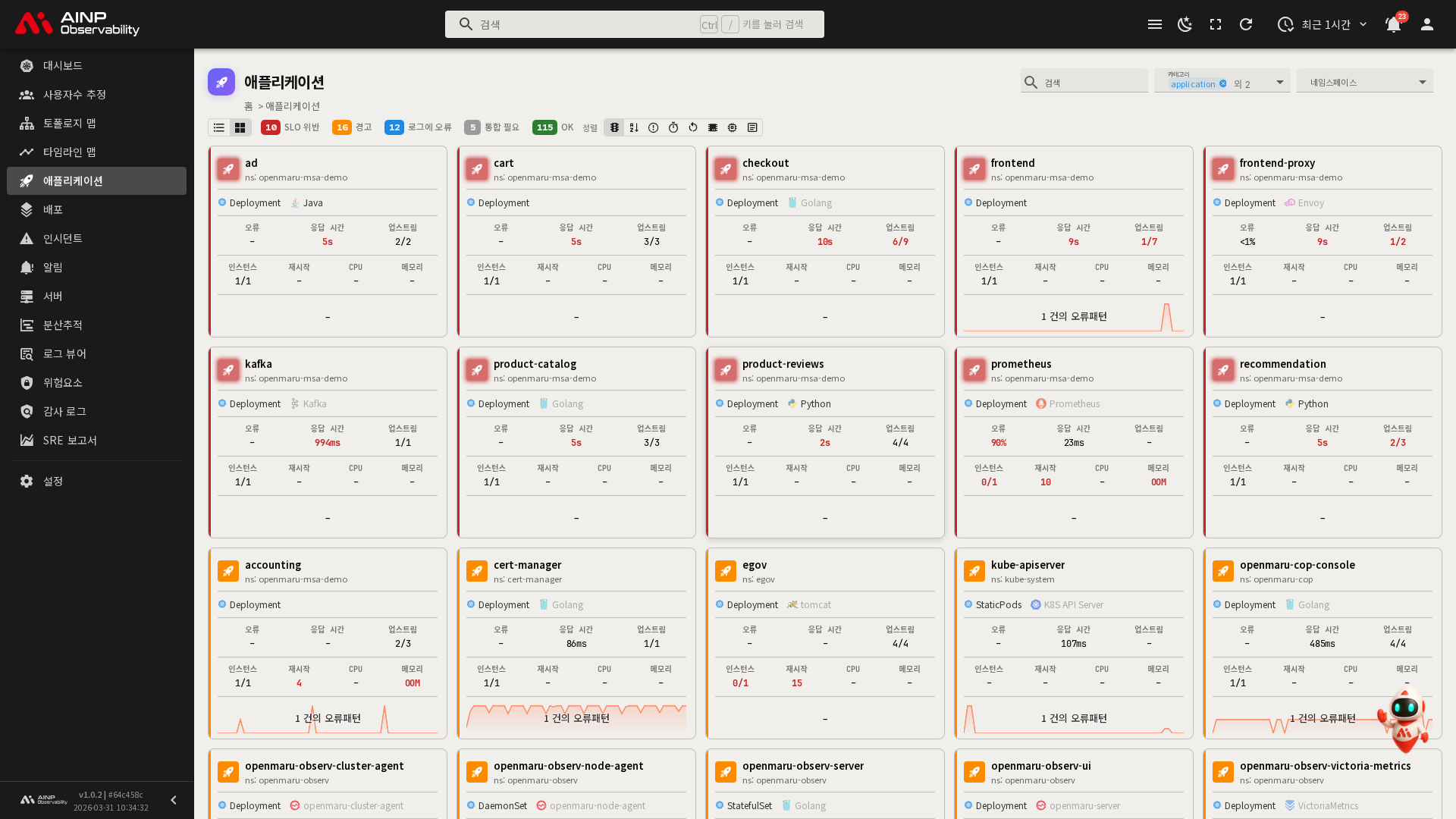
뷰 전환 버튼에서 그리드 아이콘을 클릭하면 카드 뷰로 전환됩니다. 카드 뷰는 각 애플리케이션의 상태와 주요 지표를 카드 형태로 보여줍니다. 각 카드에는 애플리케이션 이름, 상태 아이콘, 주요 메트릭(Metric) 스파크 차트가 표시되며, 카드를 클릭하면 상세 페이지로 이동합니다.
선택한 뷰 방식은 기억되어 다음 방문 시에도 유지됩니다.
카드 뷰에서는 정렬 기준을 선택할 수 있습니다.
| 정렬 기준 | 설명 |
|---|---|
| 상태 | 심각 → 경고 → 로그 오류 → 통합 필요 → 정상 순 |
| 애플리케이션 | 이름 알파벳 순 |
| 오류 | 오류 건수 내림차순 |
| 응답 시간 | 응답 시간 내림차순 |
| 재시작 | 재시작 횟수 내림차순 |
| CPU | CPU 사용률 내림차순 |
| 메모리 | �메모리 사용량 내림차순 |
| 로그 | 로그 오류 수 내림차순 |
카드 뷰 하단에는 페이지 이동 버튼과 페이지당 표시 수 설정(10 / 20 / 50 / 100 / 전체)이 있습니다.
팁: 정렬 기준을 상태로 선택하면 문제가 있는 애플리케이션이 상단에 표시되어 한눈에 파악할 수 있습니다.
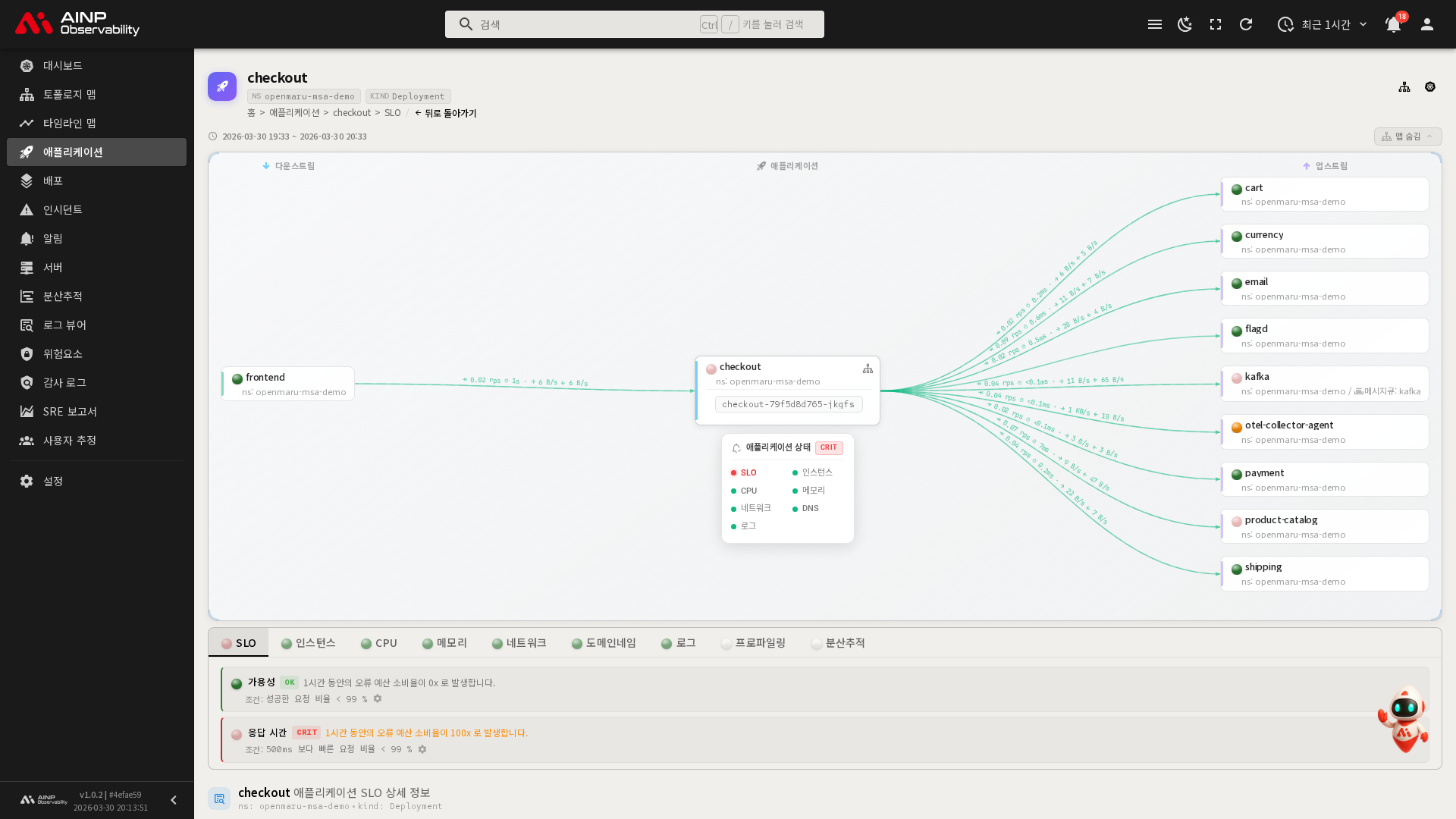
애플리케이션 상세
목록에서 애플리케이션 이름을 클릭하면 해당 애플리케이션의 상세 페이지로 이동합니다.
화면 구성
상세 페이지는 다음과 같은 영역으로 구성됩니다.
| 영역 | 설명 |
|---|---|
| 상단 헤더 | 애플리케이션명, 네임스페이스, 종류(kind), 토폴로지 맵 이동 링크 |
| 시간 범위 표시 | 현재 조회 중인 시간 범위 (최대 3일) |
| 의존성 맵(AppMap) | 애플리케이션과 연결된 서비스의 의존성 시각화 |
| 리포트 탭 | SLO, 인스턴스, CPU, 메모리, 로그 등 탭별 상세 정보 |
| 검사 상태 | 각 리포트별 검사(Inspection) 조건 충족 여부 |
| 차트 대시보드 | �선택한 탭의 메트릭 차트 위젯 |
상단 헤더에는 다음 정보와 기능이 제공됩니다.
- 애플리케이션 이름: 모니터링 대상의 이름
- ns: 소속 네임스페이스
- kind: Kubernetes 워크로드 종류(kind)
- 토폴로지 맵 열기 버튼: 클릭하면 이 애플리케이션이 강조 표시된 토폴로지 맵 화면으로 이동합니다.
- COP Console 열기 버튼: Kubernetes 리소스를 COP Console에서 직접 확인할 수 있는 외부 링크입니다. (COP Console이 설정된 경우에만 표시)
- 뒤로 돌아가기: 이전 애플리케이션 목록 화면으로 돌아갑니다.
조회 시간 범위
상세 화면 상단에는 현재 조회 중인 시간 범위가 표시됩니다. 시간 범위가 3일을 초과하면 3일 제한 배지가 표시되며, 자동으로 최근 3일 데이터만 표시됩니다. 배지 위에 마우스를 올리면 실제 조회되는 시간 범위를 확인할 수 있습니다.
선택한 시간 범위 내에 데이터가 없는 경우 안내 다이얼로그가 표시되며, 최근 1시간으로 이동 버튼을 클릭하여 최신 데이터를 확인하거나, 애플리케이션 목록으로 이동 버튼으로 목록 화면으로 돌아갈 수 있습니다.
참고: 상단 바의 시간 선택기에서 전역 시간 범위를 변경하면 상세 페이지의 데이터도 함께 업데이트됩니다.
의존성 맵(AppMap)
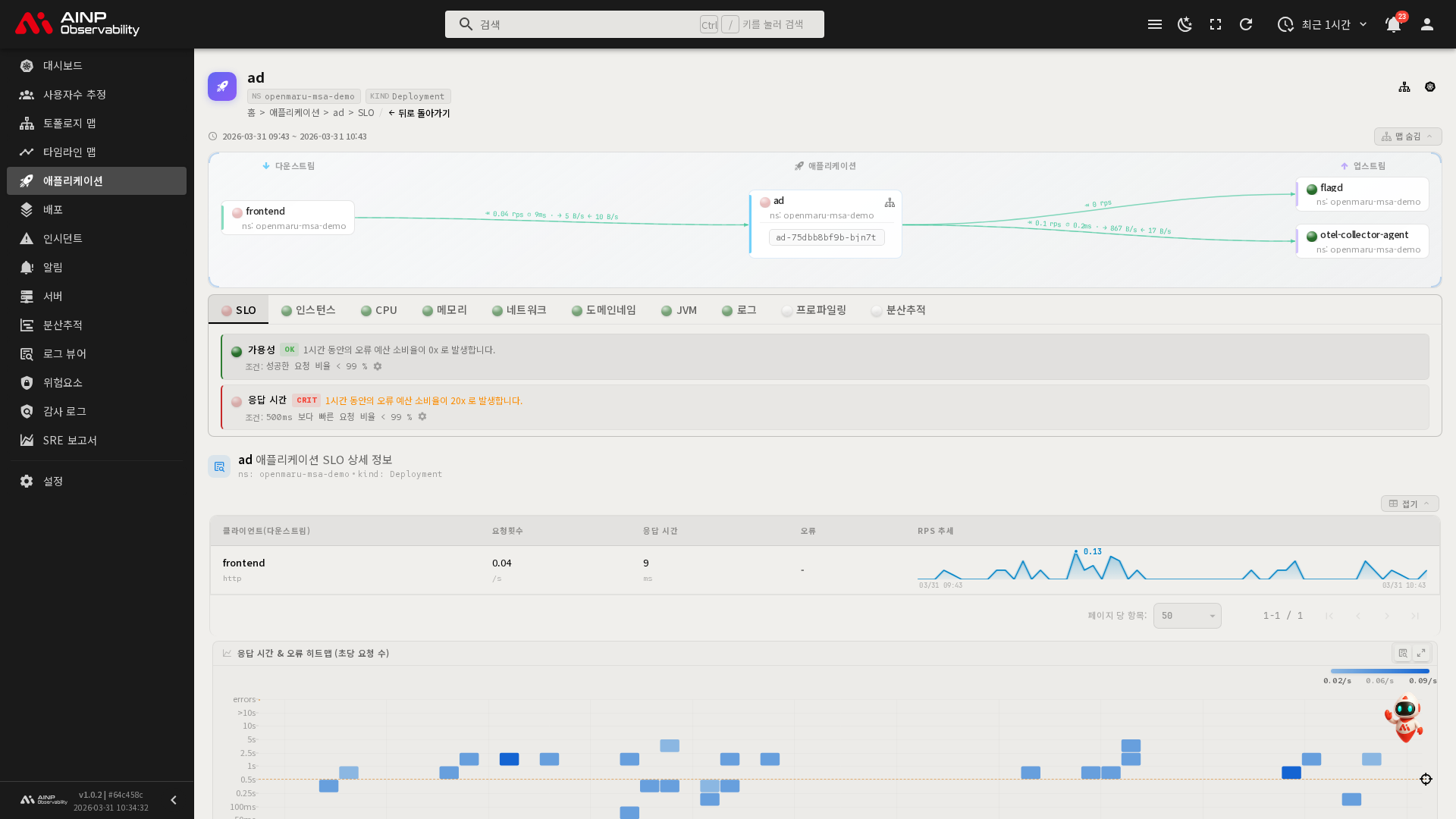
상세 화면 상단의 맵 보기 / 맵 숨김 버튼으로 의존성 맵을 켜고 끌 수 있습니다. 의존성 맵은 현재 애플리케이션과 연결된 서비스들의 관계를 시각적으로 보여줍니다.
- 업스트림(Upstream): 현재 애플리케이션이 호출하는 서비스
- 다운스트림(Downstream): 현재 애플리케이션을 호출하는 서비스
의존성 맵의 서비스 노드를 클릭하면 해당 서비스의 상세 정보를 확인하거나 토폴로지 맵에서 볼 수 있습니다.
리포트 탭
상세 페이지에서는 여러 리포트 탭이 제공됩니다. 탭 목록은 에이전트가 수집한 데이터 종류에 따라 동적으로 구성됩니다. 각 탭 이름 앞에 표시되는 상태 표시등(LED)으로 해당 리포트의 현재 상태를 빠르게 파악할 수 있습니다.
- 녹색: 정상 상태
- 주황색: 경고 수준의 이상 감지
- 빨간색: 심각한 문제 감지
- 회색: 데이터 없음 또는 미설정
SLO 탭
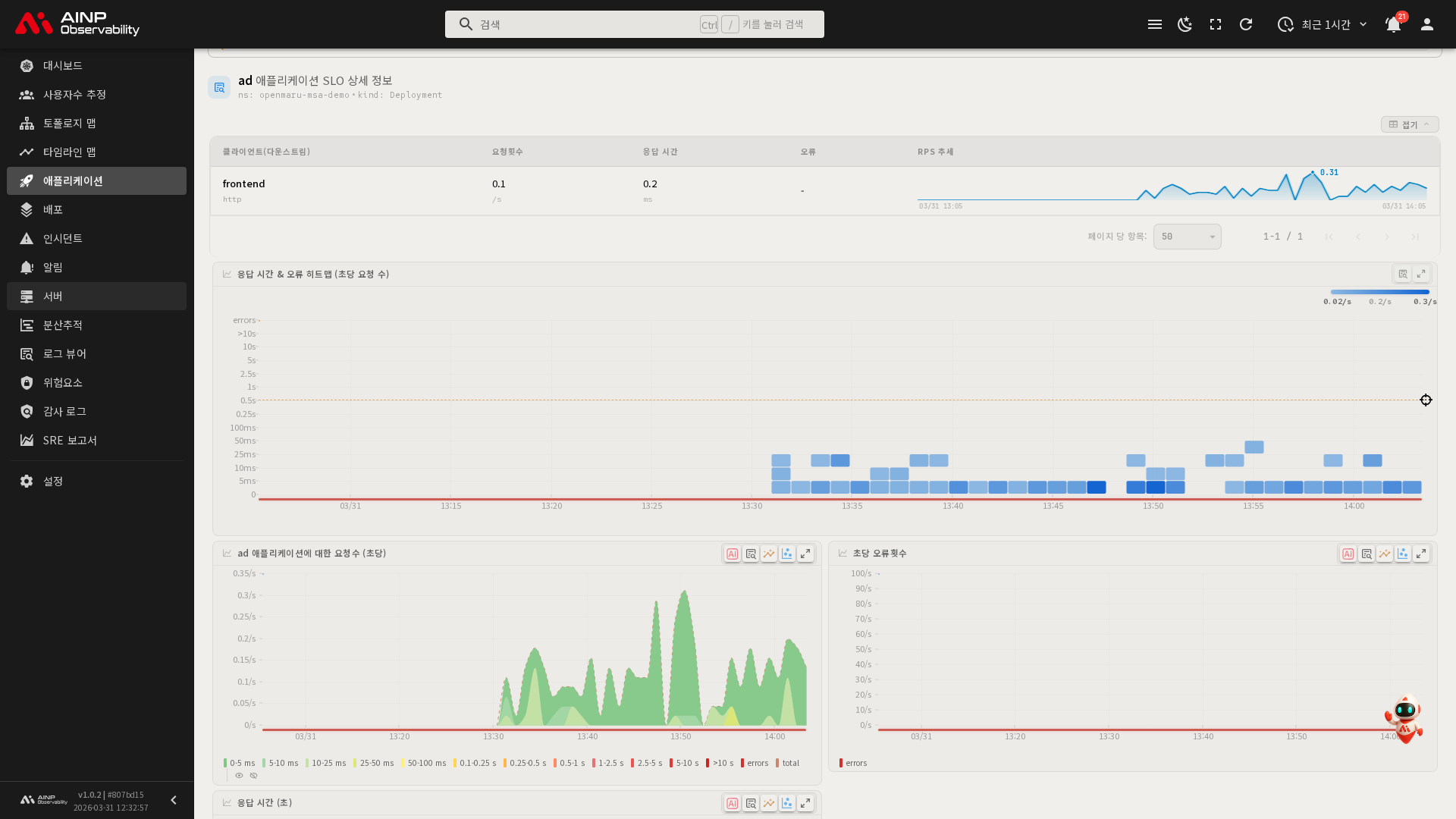
SLO 탭은 상세 페이지 진입 시 기본으로 선택되는 탭입니다. 가용성(Availability)과 응답 시간 목표 대비 현재 성능을 차트로 보여줍니다.
- 가용성 SLO: 오류 없이 처리된 요청의 비율과 목표값
- 응답 시간 SLO: 목표 응답 시간 이내로 처리된 요청의 비율
- 오류 예산(Error Budget): SLO 목표를 유지하면서 허용되는 오류의 한도
설정된 임계값(Threshold) 대비 현재 상태를 확인하고, SLO 위반 여부를 파악할 수 있습니다.
인스턴스 탭
이 애플리케이션을 구성하는 개별 인스턴스(Instance) 목록과 각 인스턴스의 CPU, 메모리, 재시작 횟수 등을 보여줍니다.
CPU 탭
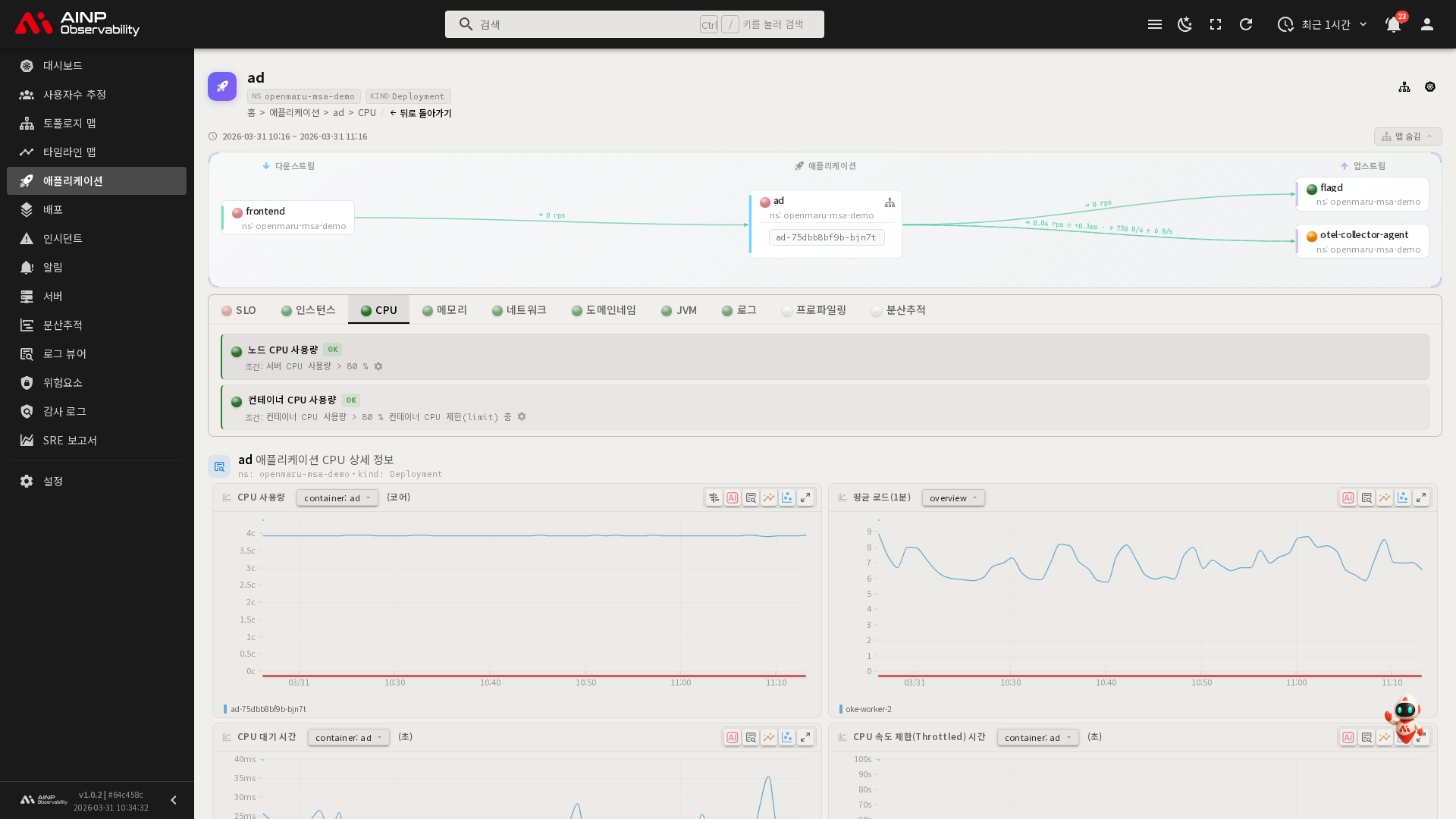
애플리케이션의 CPU 사용률 시계열 차트를 제공합니다. CPU 사용률, 스로틀링 현황, 인스턴스별 CPU 사용 추이를 분석할 수 있습니다.
메모리 탭
애플리케이션의 메모리 사용량 시계열 차트를 제공합니다. OOM(Out of Memory) 발생 여부와 메모리 누수 패턴도 확인할 수 있습니다.
로그 탭
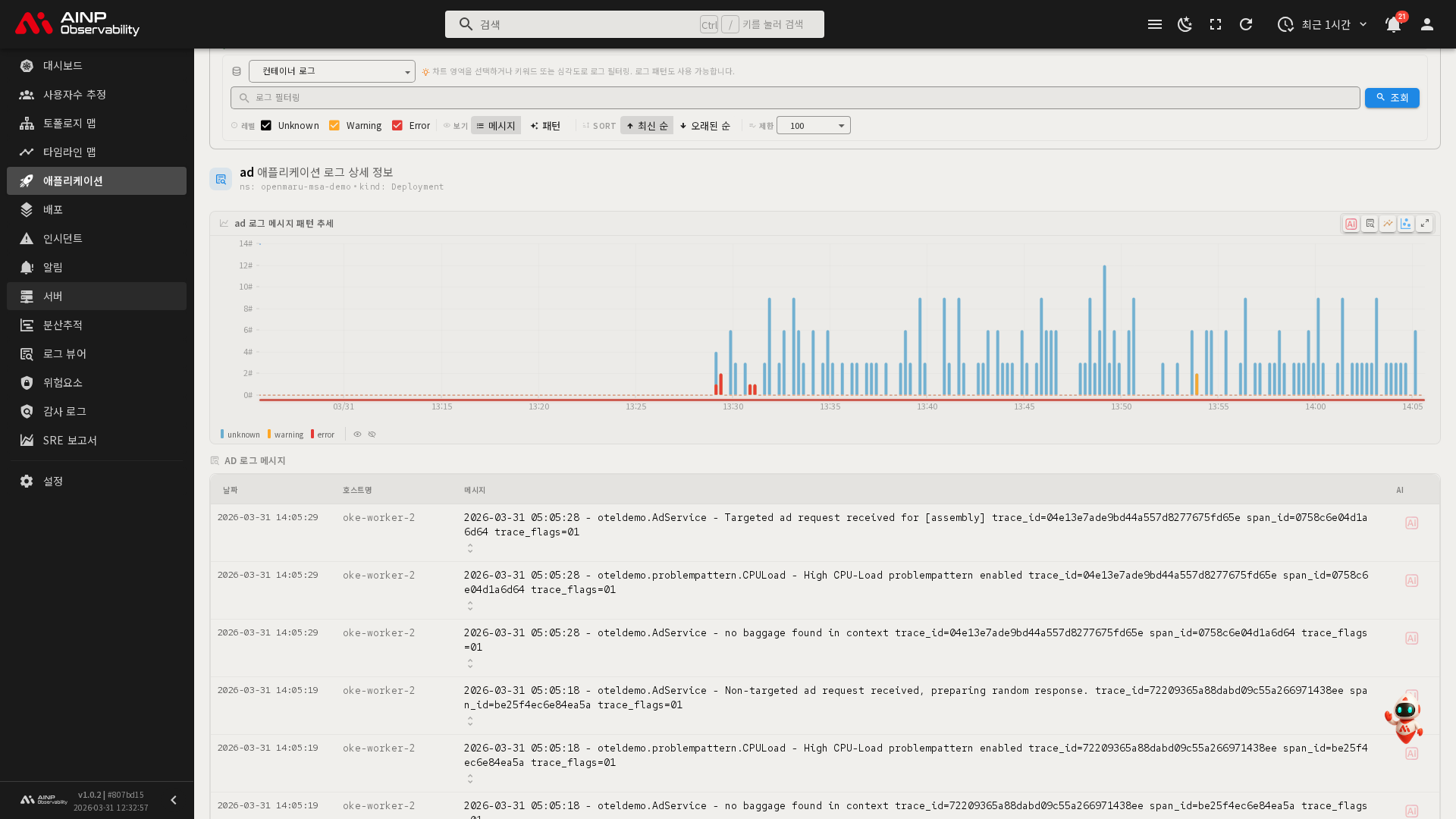
이 애플리케이션에서 발생한 로그를 조회합니다.
주요 기능:
- 소스 선택: 로그 수집 소스(agent / otel)를 선택하여 각 소스별 로그를 확인할 수 있습니다.
- 키워드 검색: 검색 필드에 키워드를 입력하고 Query 버튼을 클릭하여 특정 로그를 찾을 수 있습니다.
- 심각도 필터: Error, Warning, Info 등의 로그 레벨 체크박스로 원하는 심각도의 로그만 표시합니다.
- 로그 패턴 뷰: 유사한 구조의 로그 메시지를 자동으로 그룹화한 로그 패턴(Log Pattern)을 확인할 수 있습니다. 반복되는 오류 패턴을 한눈에 파악하는 데 유용합니다.
- 전체 로그 뷰: 로그 패턴 뷰에서 전체 뷰로 전환하면 개별 로그 메시지를 시간순으로 확인할 수 있습니다.
- 정렬: 최신순(Newest first) 또는 오래된 순(Oldest first)으로 로그 정렬 방식을 전환할 수 있습니다.
CogentAI를 활용한 로그 AI 분석
로그 탭에서는 CogentAI AI 분석 기능을 사용하여 로그 메시지의 의미를 자동으로 분석하고, 오류에 대한 원인 진단 및 해결 방안을 제안받을 수 있습니다.
로그 목록에서 AI 분석 요청하기:
- 로그 목록에서 분석하려는 로그 행 옆의 CogentAI 아이콘(AI 모양 아이콘)을 클릭합니다.
- 화면 우측 하단에 CogentAI 위젯이 자동으로 열리며, 해당 로그 메시지가 AI에게 분석 요청으로 전달됩니다.
- AI가 로그의 의미, 발생 원인, 권장 조치 등을 분석하여 결과를 표시합니다.
로그 상세 다이얼로그에서 AI 분석 요청하기:
- 로그 목록에서 로그 행을 클릭하여 상세 다이얼로그를 엽니다.
- 다이얼로그 상단의 CogentAI Insight 버튼을 클릭합니다.
- CogentAI 위젯에서 해당 로그에 대한 더 상세한 분석 결과를 확인할 수 있습니다.
로그 패턴에서 AI 분석 요청하기:
- 로그 패턴 뷰에서 특정 패턴 카드의 CogentAI 아이콘을 클릭하거나, 패턴 상세 다이얼로그의 CogentAI Insight 버튼을 클릭합니다.
- 해당 로그 패턴에 대한 AI 분석 결과가 위젯에 표시됩니다.
팁: WARN이나 ERROR 레벨의 로그를 CogentAI로 분석하면 문제 해결 절차와 관련 명령어를 포함한 구체적인 안내를 받을 수 있습니다.
CogentAI를 활용한 차트 AI 분석
각 메트릭(Metric) 차트의 우측 상단에도 CogentAI Insight 아이콘이 있습니다. 이 아이콘을 클릭하면 해당 차트의 데이터를 AI가 분석하여 이상 패턴 설명, 추세 해석, 권장 조치 등의 인사이트를 제공합니다.
- 분석하려는 메트릭 차트 우측 상단의 CogentAI Insight 아이콘(AI 모양 아이콘)을 클릭합니다.
- CogentAI 위젯이 열리며, 해당 차트의 메트릭 데이터가 분석 요청으로 전달됩니다.
- AI가 차트 데이터를 해석하여 인사이트를 제공합니다.
- 위젯에서 후속 질문을 입력하여 추가 분석을 요청할 수 있습니다.
참고: CogentAI 기능은 관리자가 CogentAI 위젯을 활성화한 경우에만 사용할 수 있습니다.
배포 탭
이 애플리케이션의 배포(Deployment) 이력을 보여줍니다. 배포 시점 전후의 메트릭 변화를 연계하여 분석할 수 있습니다.
프로파일링 탭
애플리케이션의 리소스 사용 패턴을 플레임 그래프(Flame Graph)로 시각화합니다. 자세한 내용은 프로파일링 문서를 참고하세요.
분산추적 탭
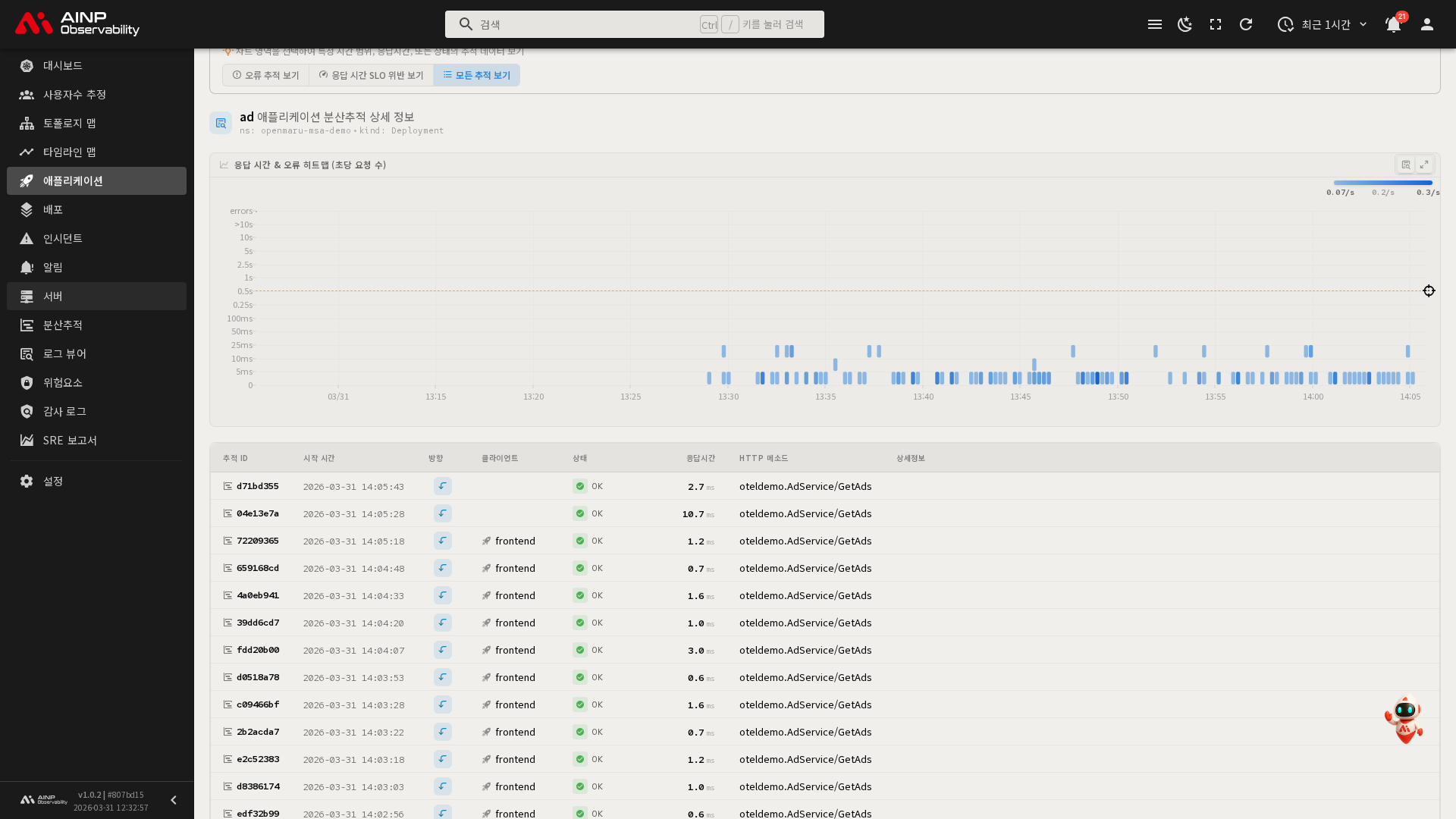
이 애플리케이션과 관련된 추적(Trace) 데이터를 히트맵과 추적 목록으로 분석합니다. 전체 프로젝트 수준의 분산추적은 사이드바의 분산추적 메뉴를 이용하세요.
RCA 탭
RCA(Root Cause Analysis, 근본원인분석) 탭은 인시던트 발생 원인을 자동으로 분석합니다. 자세한 내용은 근본원인분석(RCA) 문서를 참고하세요.
도메인네임 탭
이 애플리케이션의 DNS 쿼리 응답 시간, 오류율 등을 제공합니다.
네트워크 탭
TCP 연결 상태, 대역폭 사용량, 네트워크 라운드트립 시간(RTT) 등 네트워크 지표를 제공합니다.
데이터베이스 / 미들웨어 탭
에이전트가 데이터베이스나 미들웨어 연동을 감지한 경우 해당 리포트 탭이 추가됩니다. 자세한 내용은 데이터베이스 및 미들웨어 모니터링 문서를 참고하세요.
런타임 탭
애플리케이션의 기술 스택에 따라 런타임 전용 리포트 탭이 추가될 수 있습니다.
| 탭 | 설명 |
|---|---|
| JVM | Java 애플리케이션의 힙 메모리, 가비지 컬렉션(GC), 스레드, JVM 중지 시간 등 |
| .NET | .NET 런타임 메트릭 |
| 파이썬 | Python 런타임 메트릭 (GIL(Global Interpreter Lock) 대기 시간 등) |
참고: JVM, .NET, 파이썬 탭은 OpenTelemetry 계측이 설정된 애플리케이션에서만 표시됩니다.
스토리지 탭
디스크 I/O 부하 및 사용량 지표를 제공합니다.
검사 상태
각 리포트 탭의 상단에는 해당 영역의 검사(Inspection) 조건 충족 여부가 표시됩니다. 임계값을 초과한 항목이 있으면 경고 또는 심각 상태로 표시되며, 검사 조건의 세부 내용을 확인하거나 설정을 조정할 수 있습니다.
- 초록색 좌측 테두리: 검사 기준을 충족한 정상 상태 (OK)
- 노란색 좌측 테두리: 경고 수준의 임계값 초과 (Warning)
- 빨간색 좌측 테두리: 심각 수준의 임계값 초과 (Critical)